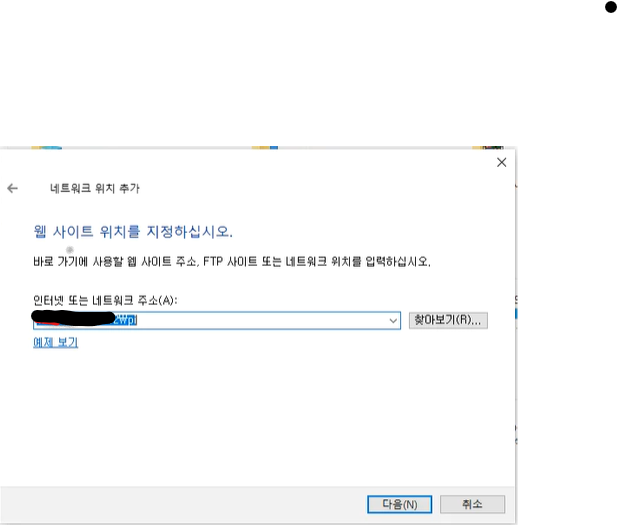
대부분 사람들이 위 방법으로 SSH를 설정한다. 하지만 이것도 한두 번이지 굉장히 귀찮은 작업이다. 이제 내가 추천하는 방법이다. 바로 Raspberry Pi imager를 이용하는 방법이다. 파일을 생성하고, 코드를 작성할 필요도 없다. 모두 GUI 선에서 해결할 수 있다.
추천 :Raspberry Pi imager를 이용하여 Raspberry Pi SSH 설정
Raspberry Pi imager 설치 (공식 홈페이지)
- 설치가 완료되면 아래와 같이 프로그램을 실행한다.
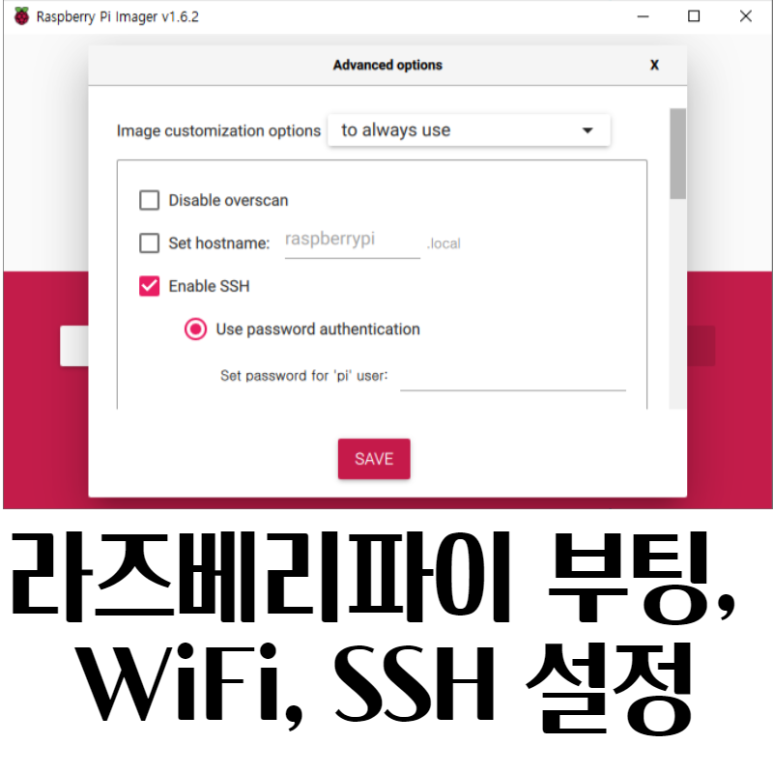
Advanced options (Ctrl + Shift + X)
- 컨트롤, 시프트, X 키를 동시에 누르면, 기본 옵션을 설정할 수 있는 창이 아래와 같이 보인다.
- 이 설정값을 매번 사용하고 싶으면 [for this session only]를 [to always use]로 변경한다.
- set hostname : host name이다. 디폴트는 raspberrypi이다. 굳이 변경하지 않아도 된다.
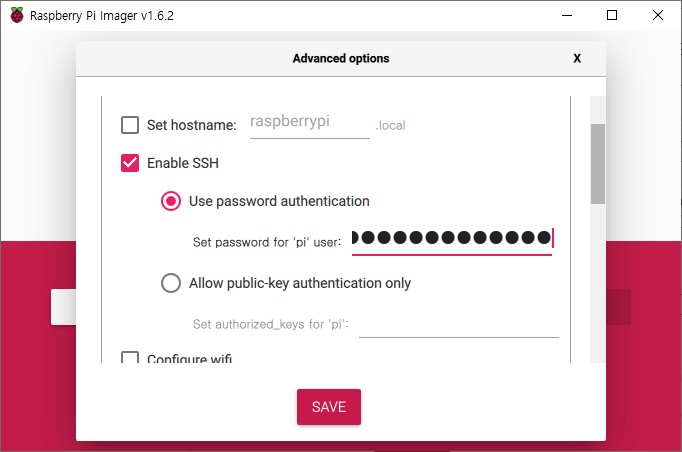
- Enable SSH : SSH 활성화, 활성화하려면, 체크하면 된다. 초기 비밀번호를 변경할 수 있다. default는 raspberry이다.
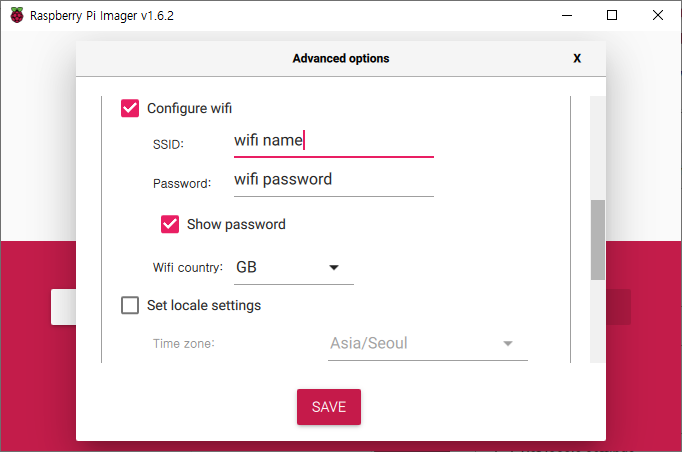
- Configure wifi : 연결하고 싶은 WiFi 이름과 비밀번호를 입력한다. 단, 5GHz WiFi는 안된다. 항상 2.4GHz WiFi를 선택해야 한다.
위 GUI 방식으로 WiFi와 SSH를 설정하면, 실수도 줄어들고 빠르고 직관적으로 내 라즈베리파이를 설정할 수 있다. 지금까지 SD카드에 일일이 설정했다면, 이제 Raspberry Pi imager를 사용하길 바란다.
# This sshd was compiled with PATH=/usr/bin:/bin:/usr/sbin:/sbin
# The strategy used for options in the default sshd_config shipped with
# OpenSSH is to specify options with their default value where
# possible, but leave them commented. Uncommented options override the
# default value.
#Port 22
#AddressFamily any
#ListenAddress 0.0.0.0
#ListenAddress ::
#HostKey /etc/ssh/ssh_host_rsa_key
#HostKey /etc/ssh/ssh_host_ecdsa_key
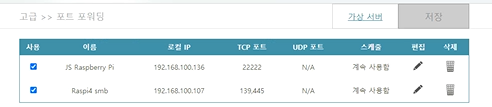
Port 139: SMB originally ran on top of NetBIOS using port 139. NetBIOS is an older transport layer that allows Windows computers to talk to each other on the same network.
Port 445: Later versions of SMB (after Windows 2000) began to use port 445 on top of a TCP stack. Using TCP allows SMB to work over the internet.
# Lint as: python3
# Copyright 2019 Google LLC
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# https://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Functions to work with detection models."""
import collections
import numpy as np
Object = collections.namedtuple('Object', ['id', 'score', 'bbox'])
class BBox(collections.namedtuple('BBox', ['xmin', 'ymin', 'xmax', 'ymax'])):
"""Bounding box.
Represents a rectangle which sides are either vertical or horizontal, parallel
to the x or y axis.
"""
__slots__ = ()
@property
def width(self):
"""Returns bounding box width."""
return self.xmax - self.xmin
@property
def height(self):
"""Returns bounding box height."""
return self.ymax - self.ymin
@property
def area(self):
"""Returns bound box area."""
return self.width * self.height
@property
def valid(self):
"""Returns whether bounding box is valid or not.
Valid bounding box has xmin <= xmax and ymin <= ymax which is equivalent to
width >= 0 and height >= 0.
"""
return self.width >= 0 and self.height >= 0
def scale(self, sx, sy):
"""Returns scaled bounding box."""
return BBox(xmin=sx * self.xmin,
ymin=sy * self.ymin,
xmax=sx * self.xmax,
ymax=sy * self.ymax)
def translate(self, dx, dy):
"""Returns translated bounding box."""
return BBox(xmin=dx + self.xmin,
ymin=dy + self.ymin,
xmax=dx + self.xmax,
ymax=dy + self.ymax)
def map(self, f):
"""Returns bounding box modified by applying f for each coordinate."""
return BBox(xmin=f(self.xmin),
ymin=f(self.ymin),
xmax=f(self.xmax),
ymax=f(self.ymax))
@staticmethod
def intersect(a, b):
"""Returns the intersection of two bounding boxes (may be invalid)."""
return BBox(xmin=max(a.xmin, b.xmin),
ymin=max(a.ymin, b.ymin),
xmax=min(a.xmax, b.xmax),
ymax=min(a.ymax, b.ymax))
@staticmethod
def union(a, b):
"""Returns the union of two bounding boxes (always valid)."""
return BBox(xmin=min(a.xmin, b.xmin),
ymin=min(a.ymin, b.ymin),
xmax=max(a.xmax, b.xmax),
ymax=max(a.ymax, b.ymax))
@staticmethod
def iou(a, b):
"""Returns intersection-over-union value."""
intersection = BBox.intersect(a, b)
if not intersection.valid:
return 0.0
area = intersection.area
return area / (a.area + b.area - area)
def input_size(interpreter):
"""Returns input image size as (width, height) tuple."""
_, height, width, _ = interpreter.get_input_details()[0]['shape']
return width, height
def input_tensor(interpreter):
"""Returns input tensor view as numpy array of shape (height, width, 3)."""
tensor_index = interpreter.get_input_details()[0]['index']
return interpreter.tensor(tensor_index)()[0]
def set_input(interpreter, size, resize):
"""Copies a resized and properly zero-padded image to the input tensor.
Args:
interpreter: Interpreter object.
size: original image size as (width, height) tuple.
resize: a function that takes a (width, height) tuple, and returns an RGB
image resized to those dimensions.
Returns:
Actual resize ratio, which should be passed to `get_output` function.
"""
width, height = input_size(interpreter)
w, h = size
scale = min(width / w, height / h)
w, h = int(w * scale), int(h * scale)
tensor = input_tensor(interpreter)
tensor.fill(0) # padding
_, _, channel = tensor.shape
tensor[:h, :w] = np.reshape(resize((w, h)), (h, w, channel))
return scale, scale
def output_tensor(interpreter, i):
"""Returns output tensor view."""
tensor = interpreter.tensor(interpreter.get_output_details()[i]['index'])()
return np.squeeze(tensor)
def get_output(interpreter, score_threshold, image_scale=(1.0, 1.0)):
"""Returns list of detected objects."""
boxes = output_tensor(interpreter, 0)
class_ids = output_tensor(interpreter, 1)
scores = output_tensor(interpreter, 2)
count = int(output_tensor(interpreter, 3))
width, height = input_size(interpreter)
image_scale_x, image_scale_y = image_scale
sx, sy = width / image_scale_x, height / image_scale_y
def make(i):
ymin, xmin, ymax, xmax = boxes[i]
return Object(
id=int(class_ids[i]),
score=float(scores[i]),
bbox=BBox(xmin=xmin,
ymin=ymin,
xmax=xmax,
ymax=ymax).scale(sx, sy).map(int))
return [make(i) for i in range(count) if scores[i] >= score_threshold]
main.py
import detect
import tflite_runtime.interpreter as tflite
import time
from PIL import Image
from PIL import ImageDraw
import cv2
import numpy as np
import time
import os
# .tflite interpreter
interpreter = tflite.Interpreter(
os.path.join(os.getcwd(), "ssd_mobilenet_v2_face_quant_postprocess_edgetpu.tflite"),
experimental_delegates=[tflite.load_delegate('libedgetpu.so.1')]
)
interpreter.allocate_tensors()
# Draws the bounding box and label for each object.
def draw_objects(image, objs):
for obj in objs:
bbox = obj.bbox
cv2.rectangle(image,(bbox.xmin, bbox.ymin), (bbox.xmax, bbox.ymax), (0, 255, 0),2)
bbox_point_w = bbox.xmin + ((bbox.xmax-bbox.xmin) // 2)
bbox_point_h = bbox.ymin + ((bbox.ymax-bbox.ymin) // 2)
cv2.circle(image, (bbox_point_w, bbox.ymax-bbox.ymin), 5, (0,0,255),-1)
cv2.putText(image, text='%d%%' % (obj.score*100), org=(bbox.xmin, bbox.ymin), fontFace=cv2.FONT_HERSHEY_SIMPLEX, fontScale=1.0, color=(0, 255, 0), thickness=1, lineType=cv2.LINE_AA)
def main():
cap = cv2.VideoCapture(0)
while True:
ret, image = cap.read()
# image reshape
image = cv2.resize(image, dsize=(320, 320), interpolation=cv2.INTER_AREA)
# image BGR to RGB
image = cv2.cvtColor(image,cv2.COLOR_BGR2RGB)
tensor = detect.input_tensor(interpreter=interpreter)[:, :] = image.copy()
tensor.fill(0) # padding
interpreter.invoke() # start
objs = detect.get_output(interpreter, 0.5, (1.0, 1.0))
if len(image):
draw_objects(image, objs)
image = cv2.cvtColor(image,cv2.COLOR_RGB2BGR)
cv2.imshow('face detector', image)
k = cv2.waitKey(30) & 0xff
if k == 27: # press 'ESC' to quit # ESC exit
break
if __name__ == '__main__':
main()
위 코드를 돌려보시면, delay가 전혀 없이 높은 성능으로 얼굴 인식을 합니다.
그렇기 때문에 얼굴 인식하고 다른 프로세스를 추가할 수 있습니다. 예를 들어 얼굴 인식하고 마스크를 검출하더라도
전혀 delay가 없습니다.
그리고 얼굴인식을 하기 전, 전처리가 없습니다.
딥러닝으로 만든 모델을 돌려보면, 실제로 적용되지 않는 경우가 많습니다.
만들어진 모델을 성능을 높이기 위해 OpenCV의 전처리를 많이 사용하는 경우가 많습니다.
하지만 이 같은 경우는 OpenCV는 사이즈를 줄이거나, 단순히 View 역할만 하고 그 외 작업은 전혀 하지 않습니다.
마스크를 쓰지 않았을 때마쓰크를 썻을 때
딥러닝을 공부하신다면, 실제로 모델을 적용해보시는 것도 많은 공부를 하는데 도움이 될 것 같습니다.