파이썬을 누구보다 좋아하고 애용하는 사람이지만 파이썬이 최고의 언어가 될 수 없는 10가지 이유를 이야기해보려 한다. 하지만 치명적인 10가지 단점이 있음에도 불구하고 전 세계 널리 사용되는 걸 보면 대단한 언어임에 틀림없다.
1. Indentation
주의할 점은 Python에서는 Indentation이 선택사항이 아니라는 것이다. 이는 If문, for문 사용 시 문제를 일으킨다. 또한 함수가 어디에서 끝나는지 잘 보이지 않는다.
2. Multiple version
Python에는 Python 2와 Python 3의 두 가지 버전이 있다.대부분의 경우 Linux에서 서로 나란히 설치되어 있기 때문에 많은 Linux distribution에서 Python 3으로 변환하는 데 시간이 걸리므로 두 가지 버전의 Python이 포함되어 출하된다.
3. 런타임 오류
Python은 인터프리터 언어로 먼저 컴파일된 후 실행되지 않는다.정확히는 실행할 때마다 컴파일되므로 실행 시 코딩 오류가 나타난다. 이 모든 것이 결국 성능 저하, 시간 소비 및 많은 테스트의 필요성으로 이어진다. 특히 주피터 노트북에서 개발을 할 때 잦은 실수를 발생시킨다.
4. White space
Python에서는 white space는 다양한 코드 수준을 나타내기 위해 광범위하게 사용된다. 단, 중괄호와 세미콜론은 시각적으로 더 매력적이고, 초보자 친화적이며, 유지보수가 용이하며, 직관적으로 이해할 수 있다.
5. ㅍLambda
Python에서 lambda사용하는 것은 다소 제한적이기 때문에 문제가 있다. Python에서 lambda는 표현식일 뿐 statement가 될 수 없다.
6. 속도
Python은 동적 타입, 인터프리터 언어이므로 속도가 느리다. 곧 배포될 예정인 Python 3.11에서 성능 향상이 많이 된다고 한다. 그래도 느릴 수밖에 없다.
7. 메모리
Python은 동적 타입 언어로, 어떤 변수로든 변할 수 있다. 하지만 그 만큼 많은 메모리를 차지하므로 메모리 낭비가 심하다.
8. 범위
Python은 동적 범위 지정과 관련이 있다. 모든 표현은 가능한 모든 컨텍스트에서 테스트해야 한다.
9. 정적 범위 설정 문제
동적 범위 지정으로 인해 발생하는 문제를 고려하여 파이썬은 정적 범위 지정으로 전환하려고 시도했지만 실패한 것 같다...
10. App development
크로스 플랫폼의 종류는 리엑티브 네이티브, 현재 주력으로 공부 중인 flutter, python으로 개발하는 kivy가 있다. 말도 아깝다. Kivy 맛보기 도전을 했는데, 바로 손절했다. 많이 사용하지 않는 데는 이유가 다 있다.
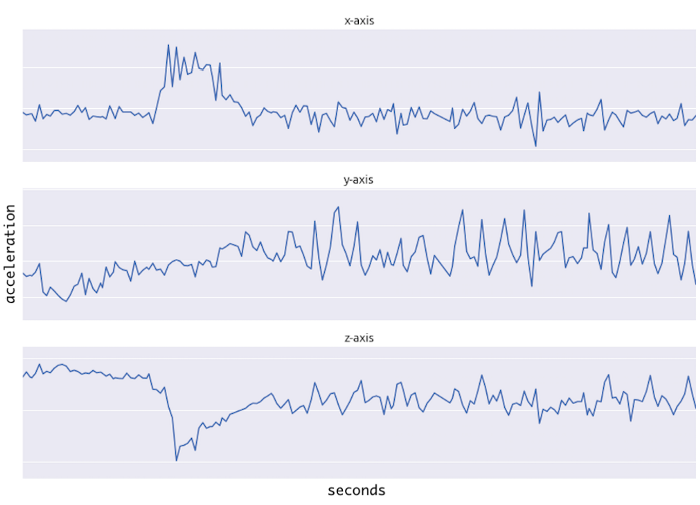
CNN은 convolution layer, pooling layer, fully connected layer로 주로 구성된다. 그 중 convolution layer와 pooling layer는 두 개의 특수 신경망 레이어로 주로 유효 특징 추출을 담당한다. 원본 데이터에서 벡터를 추출하고 원본 기능의 공간적 정보를 마이닝할 수 있다. 가속도계와 같은 1차원 데이터를 1차원 컨볼루션 신경망(Conv1D)을 사용하여 서로 다른 변수를 결합하고 변수 간의 공간적 상관 관계를 추출한다.
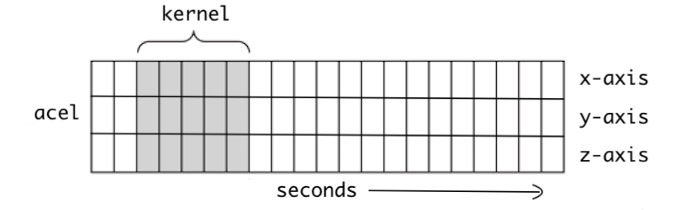
2. Conv1D
Conv1D는 그림 2와 같이 한 차원에 대해 커널 슬라이딩을 통해 공간적 상관 관계를 추출한다.
2. LSTM
LSTM은 시계열 데이터를 처리하기 위한 고전적인 딥 러닝 네트워크이다. 순환 신경망이 긴 시계열을 어느 정도 처리할 때 기울기 소실(Vanishing gradient) 문제를 해결하는 순환 신경망의 변형입니다. 장기 및 단기 기억 네트워크의 셀 구조는 그림 3과 같이 망각 게이트, 입력 게이트 및 출력 게이트가 있다.
3. LSTM
3. Conv1D + LSTM
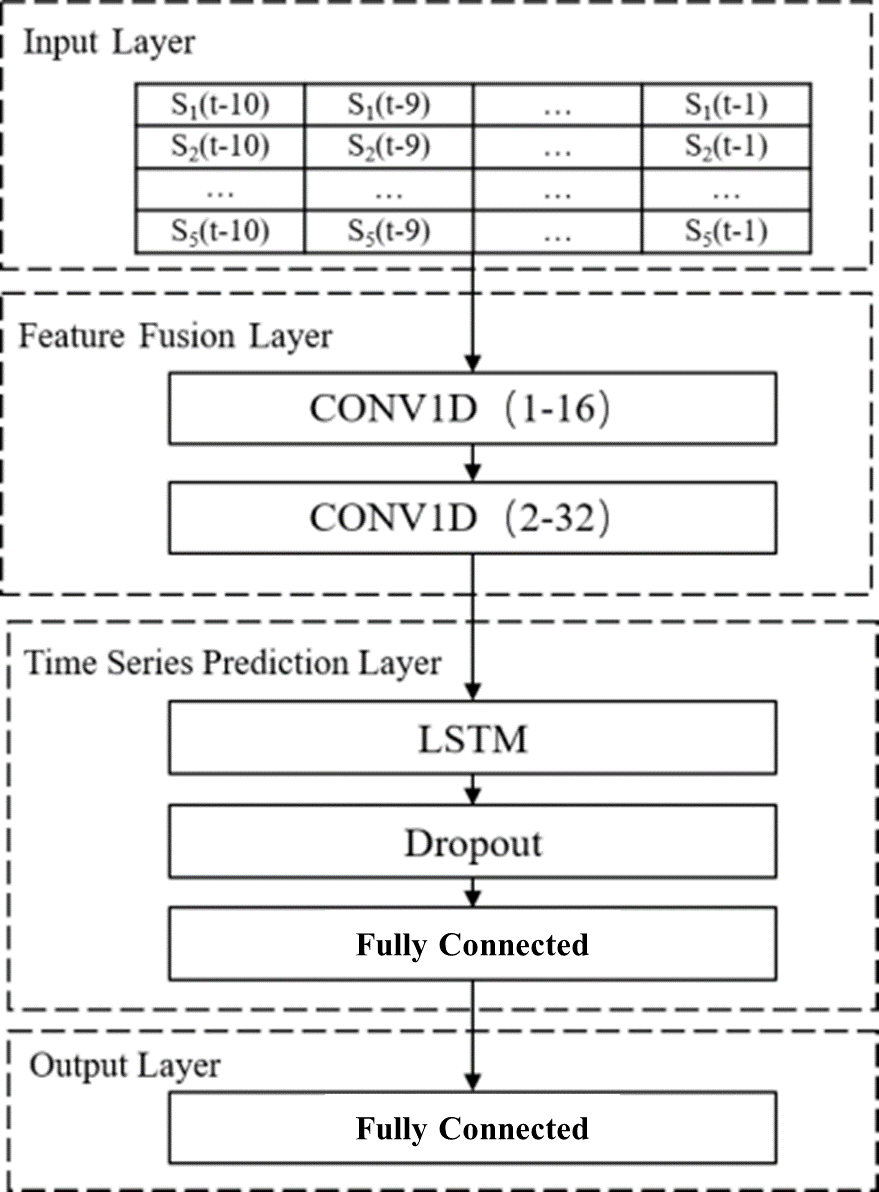
Conv1D + LSTM 모델은 그림 1과 같이 Conv1D 기반의 특징 융합 레이어, LSTM 기반 시계열 예측 레이어, output layer로 구성된다. Input layer에는 그림 0과 같은 시공간적 특성행렬이 입력된다. 각 변수는 CNN에 의해 가중치가 부여되고 변수 간의 정보가 결합된다. 과적합(Overfitting)을 피하기 위해 dropout layer가 네트워크에 추가됩니다. 모델 파라미터는 그림 4와 같이 구성한다.
4. 모델 파라미터
모델을 구성하게 되면 아래의 코드와 같이 구현할 수 있다.
import torch.nn as nn
class Conv1d_LSTM(nn.Module):
def __init__(self, in_channel=3, out_channel=1):
super(Conv1d_LSTM, self).__init__()
self.conv1d_1 = nn.Conv1d(in_channels=in_channel,
out_channels=16,
kernel_size=3,
stride=1,
padding=1)
self.conv1d_2 = nn.Conv1d(in_channels=16,
out_channels=32,
kernel_size=3,
stride=1,
padding=1)
self.lstm = nn.LSTM(input_size=32,
hidden_size=50,
num_layers=1,
bias=True,
bidirectional=False,
batch_first=True)
self.dropout = nn.Dropout(0.5)
self.dense1 = nn.Linear(50, 32)
self.dense2 = nn.Linear(32, out_channel)
def forward(self, x):
# Raw x shape : (B, S, F) => (B, 10, 3)
# Shape : (B, F, S) => (B, 3, 10)
x = x.transpose(1, 2)
# Shape : (B, F, S) == (B, C, S) // C = channel => (B, 16, 10)
x = self.conv1d_1(x)
# Shape : (B, C, S) => (B, 32, 10)
x = self.conv1d_2(x)
# Shape : (B, S, C) == (B, S, F) => (B, 10, 32)
x = x.transpose(1, 2)
self.lstm.flatten_parameters()
# Shape : (B, S, H) // H = hidden_size => (B, 10, 50)
_, (hidden, _) = self.lstm(x)
# Shape : (B, H) // -1 means the last sequence => (B, 50)
x = hidden[-1]
# Shape : (B, H) => (B, 50)
x = self.dropout(x)
# Shape : (B, 32)
x = self.fc_layer1(x)
# Shape : (B, O) // O = output => (B, 1)
x = self.fc_layer2(x)
return x