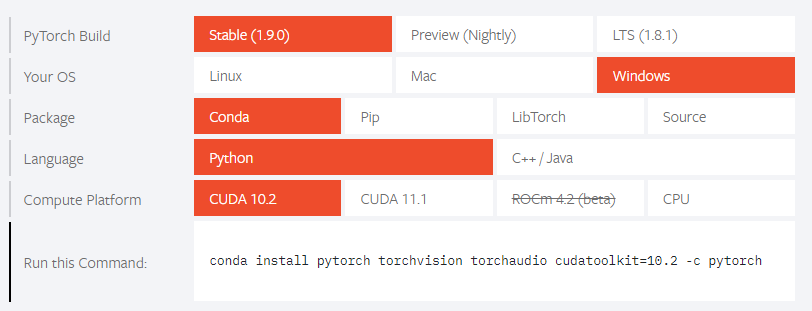
그림 참고 1:
그림 참고 2:
Understanding 1D and 3D Convolution Neural Network | Keras | by Shiva Verma | Towards Data Science
1. 데이터셋 가정
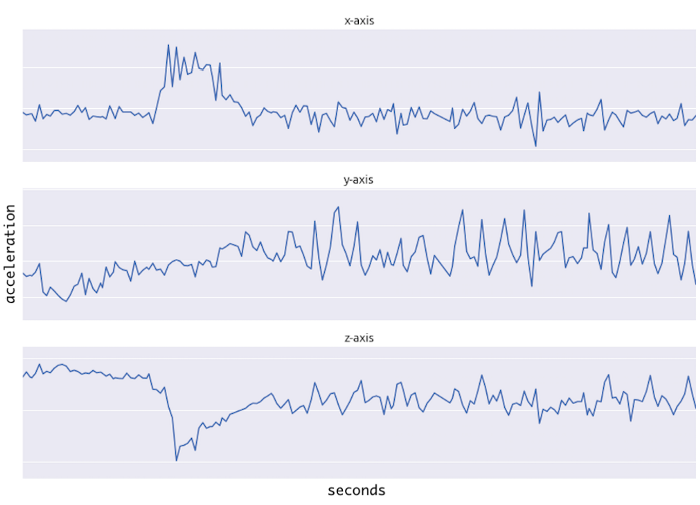
Batch size : 100000
Sequence : 10
Feature : 3 (x-axis, y-axis, z-axis)
Dataset shape : (100000, 10, 3) = (Batch size, Sequence, Feature) = (B, S, F)
2. 모델 구성
1. Conv1D
CNN은 convolution layer, pooling layer, fully connected layer로 주로 구성된다. 그 중 convolution layer와 pooling layer는 두 개의 특수 신경망 레이어로 주로 유효 특징 추출을 담당한다. 원본 데이터에서 벡터를 추출하고 원본 기능의 공간적 정보를 마이닝할 수 있다. 가속도계와 같은 1차원 데이터를 1차원 컨볼루션 신경망(Conv1D)을 사용하여 서로 다른 변수를 결합하고 변수 간의 공간적 상관 관계를 추출한다.
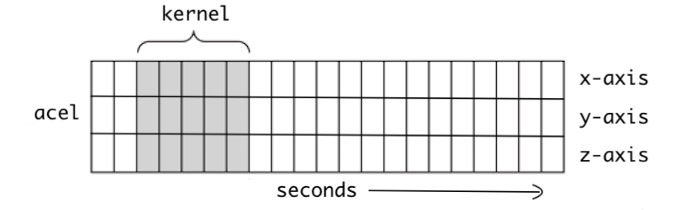
Conv1D는 그림 2와 같이 한 차원에 대해 커널 슬라이딩을 통해 공간적 상관 관계를 추출한다.
2. LSTM
LSTM은 시계열 데이터를 처리하기 위한 고전적인 딥 러닝 네트워크이다. 순환 신경망이 긴 시계열을 어느 정도 처리할 때 기울기 소실(Vanishing gradient) 문제를 해결하는 순환 신경망의 변형입니다. 장기 및 단기 기억 네트워크의 셀 구조는 그림 3과 같이 망각 게이트, 입력 게이트 및 출력 게이트가 있다.

3. Conv1D + LSTM
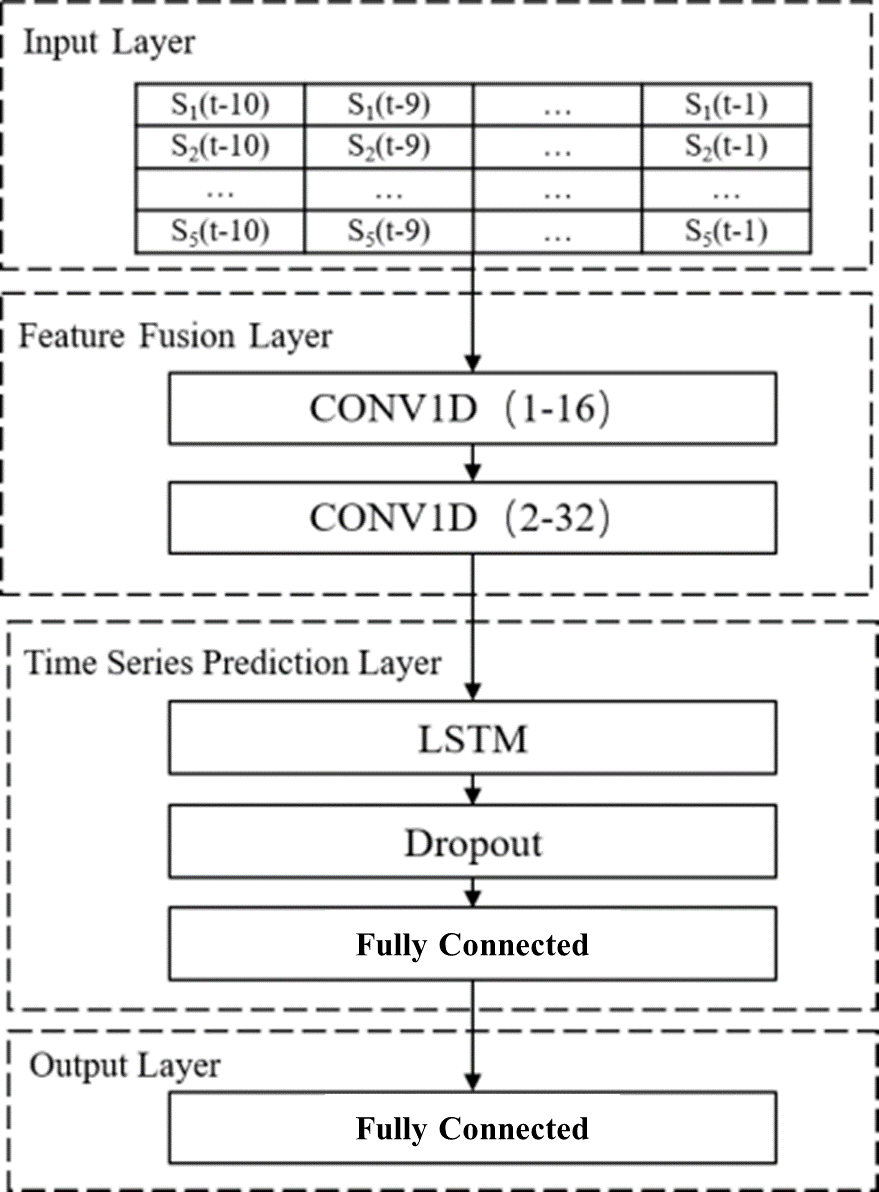
Conv1D + LSTM 모델은 그림 1과 같이 Conv1D 기반의 특징 융합 레이어, LSTM 기반 시계열 예측 레이어, output layer로 구성된다. Input layer에는 그림 0과 같은 시공간적 특성행렬이 입력된다. 각 변수는 CNN에 의해 가중치가 부여되고 변수 간의 정보가 결합된다. 과적합(Overfitting)을 피하기 위해 dropout layer가 네트워크에 추가됩니다. 모델 파라미터는 그림 4와 같이 구성한다.

모델을 구성하게 되면 아래의 코드와 같이 구현할 수 있다.
import torch.nn as nn
class Conv1d_LSTM(nn.Module):
def __init__(self, in_channel=3, out_channel=1):
super(Conv1d_LSTM, self).__init__()
self.conv1d_1 = nn.Conv1d(in_channels=in_channel,
out_channels=16,
kernel_size=3,
stride=1,
padding=1)
self.conv1d_2 = nn.Conv1d(in_channels=16,
out_channels=32,
kernel_size=3,
stride=1,
padding=1)
self.lstm = nn.LSTM(input_size=32,
hidden_size=50,
num_layers=1,
bias=True,
bidirectional=False,
batch_first=True)
self.dropout = nn.Dropout(0.5)
self.dense1 = nn.Linear(50, 32)
self.dense2 = nn.Linear(32, out_channel)
def forward(self, x):
# Raw x shape : (B, S, F) => (B, 10, 3)
# Shape : (B, F, S) => (B, 3, 10)
x = x.transpose(1, 2)
# Shape : (B, F, S) == (B, C, S) // C = channel => (B, 16, 10)
x = self.conv1d_1(x)
# Shape : (B, C, S) => (B, 32, 10)
x = self.conv1d_2(x)
# Shape : (B, S, C) == (B, S, F) => (B, 10, 32)
x = x.transpose(1, 2)
self.lstm.flatten_parameters()
# Shape : (B, S, H) // H = hidden_size => (B, 10, 50)
_, (hidden, _) = self.lstm(x)
# Shape : (B, H) // -1 means the last sequence => (B, 50)
x = hidden[-1]
# Shape : (B, H) => (B, 50)
x = self.dropout(x)
# Shape : (B, 32)
x = self.fc_layer1(x)
# Shape : (B, O) // O = output => (B, 1)
x = self.fc_layer2(x)
return x
'Python > Deep Learning' 카테고리의 다른 글
| [딥러닝] 딥러닝 모델을 간단하게 시각화하는 프로그램, Netron | Pytorch, ONNX (0) | 2022.03.05 |
|---|---|
| [Deep Learning] 분류 학습을 위해 골고루 훈련 및 테스트 데이터셋 분할하는 방법 (0) | 2022.03.01 |
| 주피터 노트북 테마 툴바(Toolbar) 고정 - 주피터 노트북 개인 딥러닝 서버 만들기 ! (예외편) (0) | 2021.07.20 |
| 주피터 노트북 개인 딥러닝 서버 만들기 ! (3) with Window10, Pytorch (2) | 2021.07.19 |
| 주피터 노트북 개인 딥러닝 서버 만들기 ! (2) with Window10, Pytorch (1) | 2021.07.16 |