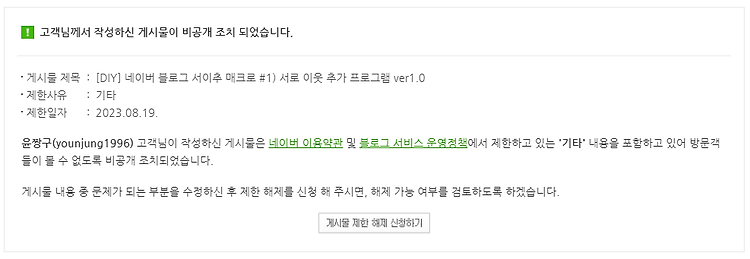
네이버 블로그 자동 공감 누르기
·
🐍 Python/Project
제목 그대로다. 네이버 블로그도 인스타, 트위터처럼 좋아요 버튼이 있다. 바로 공감하기 이다. 말 그대로 나와 이웃된 블로거들의 포스팅에 공감을 눌러주는 매크로 프로그램이다. 아래 영상은 데모영상이다. https://youtu.be/1_RBb1bjl48?si=VR2HDsotghQVmPEj