안녕하세요.
오늘은 LSTM을 이용해서 삼성전자 주가를 예측해보겠습니다.
큰 Dataset은 따로 필요하지 않으니 부담 갖지 않고 하시면 될 것 같습니다.
아래는 본문 글입니다.
LSTM이 어떻게 동작을 하는지 자세히 아시고 싶으시면 아래 블로그를 추천드립니다.
dgkim5360.tistory.com/entry/understanding-long-short-term-memory-lstm-kr
Long Short-Term Memory (LSTM) 이해하기
이 글은 Christopher Olah가 2015년 8월에 쓴 글을 우리 말로 번역한 것이다. Recurrent neural network의 개념을 쉽게 설명했고, 그 중 획기적인 모델인 LSTM을 이론적으로 이해할 수 있도록 좋은 그림과 함께
dgkim5360.tistory.com
1. 라이브러리
import numpy as np
import pandas as pd
import pandas_datareader.data as pdr
import matplotlib.pyplot as plt
import datetime
import torch
import torch.nn as nn
from torch.autograd import Variable
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
no module pandas_datareaderno module named 'pandas_datareader'
pandas가 깔려 있는데, 위 문구가 뜬다면 pip install pandas_datareader로 다운로드합니다.
[파이썬 응용] pandas_datareader의 error문 : FutureWarning: pandas.util.testing is deprecated. Use the functions in the pu
안녕하세요. pandas_datareader을 이용해서 데이터 처리를 하기 위해 아래 문구처럼 에러문이 뜨는 경우가 있습니다. FutureWarning: pandas.util.testing is deprecated. Use the functions in the public API at..
coding-yoon.tistory.com
옛날에는 Pandas를 깔면 자동으로 깔렸었는데, 이번에 아예 분리가 된 것 같습니다.
2. 삼성 전자 주식 불러오기
start = (2000, 1, 1) # 2020년 01년 01월
start = datetime.datetime(*start)
end = datetime.date.today() # 현재
# yahoo 에서 삼성 전자 불러오기
df = pdr.DataReader('005930.KS', 'yahoo', start, end)
df.head(5)
df.tail(5)
df.Close.plot(grid=True)



삼성 전자 종가를 2000년부터 2020년으로 한 번에 보니 미쳐 날 뛰네요. 지금이라도 이 흐름을 타야 하지 않을까요.
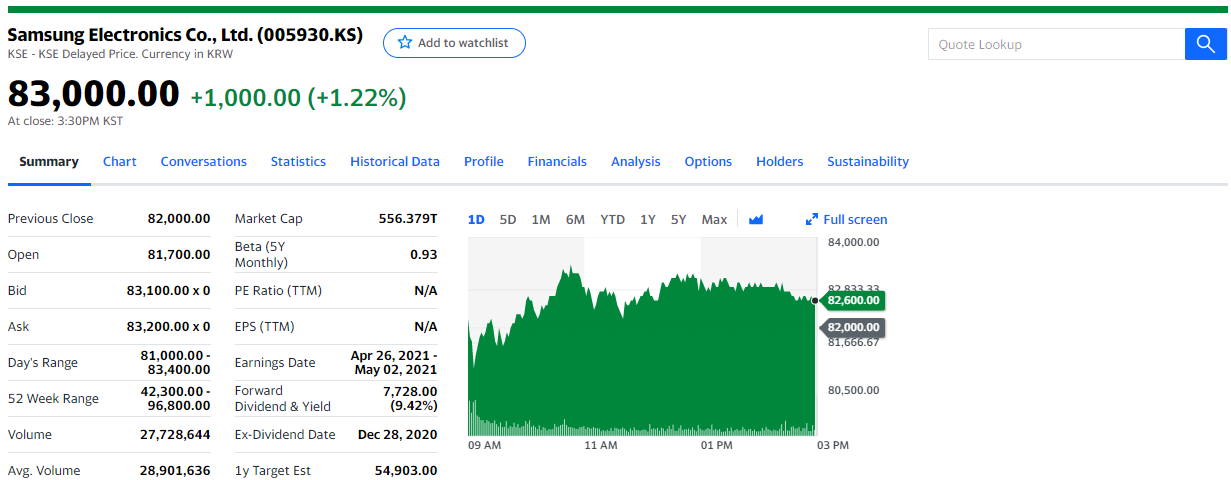
십 만전자 가자!!
혹시 다른 주식도 하고 싶으시면 야후 파이낸시에서 찾아보시는 것도 추천드립니다.
Yahoo Finance - Stock Market Live, Quotes, Business & Finance News
At Yahoo Finance, you get free stock quotes, up-to-date news, portfolio management resources, international market data, social interaction and mortgage rates that help you manage your financial life.
finance.yahoo.com
그리고 학습된 모델이 성능을 확인하기 위해서 위 데이터(현재 약 5296개)를 Train(학습하고자 하는 데이터)를 0부터 4499까지, Test(성능 테스트하는 데이터)는 4500부터 5295개 까지 데이터로 분류합니다.

오늘자 대략, 노란색 선 정도까지 데이터를 가지고 학습을 하고, 노란색 선 이후부터 예측을 할 것입니다.
과연 내려가고 올라가는 포인트를 잘 예측할 수 있을지 궁금합니다.
3. 데이터셋 준비하기
"""
저도 주식을 잘 모르기 때문에 참고해주시면 좋을 것 같습니다.
open 시가
high 고가
low 저가
close 종가
volume 거래량
Adj Close 주식의 분할, 배당, 배분 등을 고려해 조정한 종가
확실한건 거래량(Volume)은 데이터에서 제하는 것이 중요하고,
Y 데이터를 Adj Close로 정합니다. (종가로 해도 된다고 생각합니다.)
"""
X = df.drop(columns='Volume')
y = df.iloc[:, 5:6]
print(X)
print(y)

"""
학습이 잘되기 위해 데이터 정규화
StandardScaler 각 특징의 평균을 0, 분산을 1이 되도록 변경
MinMaxScaler 최대/최소값이 각각 1, 0이 되도록 변경
"""
from sklearn.preprocessing import StandardScaler, MinMaxScaler
mm = MinMaxScaler()
ss = StandardScaler()
X_ss = ss.fit_transform(X)
y_mm = mm.fit_transform(y)
# Train Data
X_train = X_ss[:4500, :]
X_test = X_ss[4500:, :]
# Test Data
"""
( 굳이 없어도 된다. 하지만 얼마나 예측데이터와 실제 데이터의 정확도를 확인하기 위해
from sklearn.metrics import accuracy_score 를 통해 정확한 값으로 확인할 수 있다. )
"""
y_train = y_mm[:4500, :]
y_test = y_mm[4500:, :]
print("Training Shape", X_train.shape, y_train.shape)
print("Testing Shape", X_test.shape, y_test.shape) 
"""
torch Variable에는 3개의 형태가 있다.
data, grad, grad_fn 한 번 구글에 찾아서 공부해보길 바랍니다.
"""
X_train_tensors = Variable(torch.Tensor(X_train))
X_test_tensors = Variable(torch.Tensor(X_test))
y_train_tensors = Variable(torch.Tensor(y_train))
y_test_tensors = Variable(torch.Tensor(y_test))
X_train_tensors_final = torch.reshape(X_train_tensors, (X_train_tensors.shape[0], 1, X_train_tensors.shape[1]))
X_test_tensors_final = torch.reshape(X_test_tensors, (X_test_tensors.shape[0], 1, X_test_tensors.shape[1]))
print("Training Shape", X_train_tensors_final.shape, y_train_tensors.shape)
print("Testing Shape", X_test_tensors_final.shape, y_test_tensors.shape) 
4. GPU 준비하기 (없으면 CPU로 돌리면 됩니다.)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") # device
print(torch.cuda.get_device_name(0))
5. LSTM 네트워크 구성하기
class LSTM1(nn.Module):
def __init__(self, num_classes, input_size, hidden_size, num_layers, seq_length):
super(LSTM1, self).__init__()
self.num_classes = num_classes #number of classes
self.num_layers = num_layers #number of layers
self.input_size = input_size #input size
self.hidden_size = hidden_size #hidden state
self.seq_length = seq_length #sequence length
self.lstm = nn.LSTM(input_size=input_size, hidden_size=hidden_size,
num_layers=num_layers, batch_first=True) #lstm
self.fc_1 = nn.Linear(hidden_size, 128) #fully connected 1
self.fc = nn.Linear(128, num_classes) #fully connected last layer
self.relu = nn.ReLU()
def forward(self,x):
h_0 = Variable(torch.zeros(self.num_layers, x.size(0), self.hidden_size)).to(device) #hidden state
c_0 = Variable(torch.zeros(self.num_layers, x.size(0), self.hidden_size)).to(device) #internal state
# Propagate input through LSTM
output, (hn, cn) = self.lstm(x, (h_0, c_0)) #lstm with input, hidden, and internal state
hn = hn.view(-1, self.hidden_size) #reshaping the data for Dense layer next
out = self.relu(hn)
out = self.fc_1(out) #first Dense
out = self.relu(out) #relu
out = self.fc(out) #Final Output
return out
위 코드는 복잡해 보이지만, 실상 하나씩 확인해보면 굉장히 연산이 적은 네트워크입니다.
시계열 데이터이지만, 간단한 구성을 위해 Sequence Length도 1이고, LSTM Layer도 1이기 때문에 굉장히 빨리 끝납니다. 아마 본문 작성자가 CPU환경에서도 쉽게 따라 할 수 있게 간단하게 작성한 것 같습니다.
아래는 Pytorch로 RNN을 사용하는 방법을 적었지만, LSTM과 동일합니다.
기본 동작 원리만 이해하시면, 쉽게 따라 하실 수 있습니다.
[딥러닝] RNN with PyTorch ( RNN 기본 구조, 사용 방법 )
오늘은 Pytorch를 통해 RNN을 알아보겠습니다. https://www.youtube.com/watch?v=bPRfnlG6dtU&t=2674s RNN의 기본구조를 모르시면 위 링크를 보시는걸 추천드립니다. Pytorch document에 RNN을 확인하겠습니다. ht..
coding-yoon.tistory.com
5. 네트워크 파라미터 구성하기
num_epochs = 30000 #1000 epochs
learning_rate = 0.00001 #0.001 lr
input_size = 5 #number of features
hidden_size = 2 #number of features in hidden state
num_layers = 1 #number of stacked lstm layers
num_classes = 1 #number of output classes lstm1 = LSTM1(num_classes, input_size, hidden_size, num_layers, X_train_tensors_final.shape[1]).to(device)
loss_function = torch.nn.MSELoss() # mean-squared error for regression
optimizer = torch.optim.Adam(lstm1.parameters(), lr=learning_rate) # adam optimizer
6. 학습하기
for epoch in range(num_epochs):
outputs = lstm1.forward(X_train_tensors_final.to(device)) #forward pass
optimizer.zero_grad() #caluclate the gradient, manually setting to 0
# obtain the loss function
loss = loss_function(outputs, y_train_tensors.to(device))
loss.backward() #calculates the loss of the loss function
optimizer.step() #improve from loss, i.e backprop
if epoch % 100 == 0:
print("Epoch: %d, loss: %1.5f" % (epoch, loss.item()))
7. 예측하기
df_X_ss = ss.transform(df.drop(columns='Volume'))
df_y_mm = mm.transform(df.iloc[:, 5:6])
df_X_ss = Variable(torch.Tensor(df_X_ss)) #converting to Tensors
df_y_mm = Variable(torch.Tensor(df_y_mm))
#reshaping the dataset
df_X_ss = torch.reshape(df_X_ss, (df_X_ss.shape[0], 1, df_X_ss.shape[1]))train_predict = lstm1(df_X_ss.to(device))#forward pass
data_predict = train_predict.data.detach().cpu().numpy() #numpy conversion
dataY_plot = df_y_mm.data.numpy()
data_predict = mm.inverse_transform(data_predict) #reverse transformation
dataY_plot = mm.inverse_transform(dataY_plot)
plt.figure(figsize=(10,6)) #plotting
plt.axvline(x=4500, c='r', linestyle='--') #size of the training set
plt.plot(dataY_plot, label='Actuall Data') #actual plot
plt.plot(data_predict, label='Predicted Data') #predicted plot
plt.title('Time-Series Prediction')
plt.legend()
plt.show()

빨간색 선 이후부터 모델이 예측을 한 것인데 나름 비슷하게 나온 것 같습니다.
하지만 인공지능이라도 팔만 전자는 예상하지 못했나 봅니다.
'🐍 Python > Deep Learning' 카테고리의 다른 글
| [무선 통신] UWB LOS/NLOS Classification Using Deep Learning Method (2) (0) | 2021.03.10 |
|---|---|
| [Pytorch] RNN에서 Tanh말고 Sigmoid나 ReLU를 사용하면 안될까? (1) | 2021.02.04 |
| [딥러닝] Depth-wise Separable Convolution 원리(Pytorch 구현) (2) | 2021.01.22 |
| [딥러닝] DeepLearning CNN BottleNeck 원리(Pytorch 구현) (0) | 2021.01.13 |
| [딥러닝] 저해상도를 고해상도로 이미지 만들기(Preprocess)! Super Resolution! (1) | 2020.10.01 |