안녕하세요. 저번 Depthwise Separable Convolution 기법에 대해 글을 올렸습니다.
오늘은 이 기법을 사용한 Xception 논문에 대해 리뷰하도록 하겠습니다.
CVPR 2017 Open Access Repository
Francois Chollet; Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017, pp. 1251-1258 We present an interpretation of Inception modules in convolutional neural networks as being an intermediate step in-between regular
openaccess.thecvf.com
우선, Xception을 리뷰하기 전 Inception에 대해 간단히 짚고 넘어가겠습니다.
Inception 모듈로 2014년도에 가장 높은 성적을 거둔 GoogleLeNet 을 만들었습니다.
1. Inception Module

인셉션 모듈은 이전 단계의 활성화 지도에 다양한 필터 크기(Kernel_Size)로 합성곱 연산을 적용하는 방식입니다.
쉽게 표현하면, 강아지 사진에서 귀, 코, 눈 등의 특징을 다른 방향으로 보는 것입니다.
다른 방향에서 보기 때문에, 같은 강아지 사진에서 다른 특성들을 추출할 수 있습니다.
인셉션은 적은 파라미터로 다양한 특징값을 추출하는데 의미가 있습니다.
class InceptionModule(nn.Module):
def __init__(self, n_channels=10):
super(InceptionModule, self).__init__()
# Sequential : 연산을 차례로 수행
self.conv2d_3k = nn.Conv2d(in_channels=n_channels,
out_channels=n_channels,
kernel_size=3,
padding=1)
self.conv2d_1k = nn.Conv2d(in_channels=n_channels,
out_channels=n_channels,
kernel_size=1)
self.avgpool2d = nn.AvgPool2d(kernel_size=1)
def forward(self, x):
y1 = self.conv2d_1k(x)
y2_1 = self.conv2d_1k(x)
y2_2 = self.conv2d_3k(y2_1)
y3_1 = self.avgpool2d(x)
y3_2 = self.conv2d_3k(y3_1)
y4_1 = self.conv2d_1k(x)
y4_2 = self.conv2d_3k(y4_1)
y4_3 = self.conv2d_3k(y4_2)
out = torch.cat([y1, y2_2, y3_2, y4_3], dim=1)
return out
2. 단순한 Inception Module

저번 글에 나온 Depthwise Separable Convolution의 핵심 개념인 spartial correlation(3x3 convolution)과 cross channel correlation(1x1 convolution)이 등장합니다.
여기 Standard Convolution과 차별 점은 서로가 매핑(mapping)되지 않고 독립적으로 수행하는 것입니다.
Figure1의 복잡함을 최대한 Simple하게 가는데 의미가 있습니다.
class SimplyInceptionModule(nn.Module):
def __init__(self, n_channels=10):
super(SimplyInceptionModule, self).__init__()
# Sequential : 연산을 차례로 수행
self.conv2d_3k = nn.Conv2d(in_channels=n_channels,
out_channels=n_channels,
kernel_size=3,
padding=1)
self.conv2d_1k = nn.Conv2d(in_channels=n_channels,
out_channels=n_channels,
kernel_size=1)
def forward(self, x):
y1_1 = self.conv2d_1k(x)
y1_2 = self.conv2d_3k(y1_1)
y2_1 = self.conv2d_1k(x)
y2_2 = self.conv2d_3k(y2_1)
y3_1 = self.conv2d_1k(x)
y3_2 = self.conv2d_3k(y3_1)
out = torch.cat([y1_2, y2_2, y3_2], dim=1)
return out3. 더 단순한 Inception module

Figure2에서 1x1 Convolution을 Input마다 독립적으로 수행했다면,
Figure3에서는 1x1 Convolution을 input 한 번만을 수행합니다.
1x1 Convolution 수행한 output을 (그룹으로) 분리하여 3x3 Convolution을 수행합니다.
Figure2를 변형하여 더 Simple하게!
SimplyInceptionModule3 = nn.Sequential(
nn.Conv2d(in_channels=9,
out_channels=9,
kernel_size=1,
bias=False),
nn.ReLU(),
nn.Conv2d(in_channels=9,
out_channels=9,
kernel_size=3,
groups=3,
bias=False),
nn.ReLU()
)
이 논문에서 중요한 부분이라고 생각되는 부분입니다.
This observation naturally raises the question:
이 관찰은 당연히 문제를 제기합니다.
what is the effect of the number of segments in the partition (and their size)?
파티션의 세그먼트 수 (및 크기)는 어떤 영향을 미칩니까?
4. Extreme version of Inception module
Figure3에서 Output Channels를 최대로 그룹을 지어 분리하여 수행하면 어떨까?
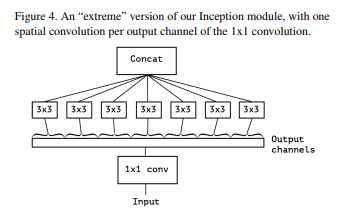
위 논문의 질문의 가설로, 파티션의 세그먼트를 최대 단위로 수행한다면 어떻게 되는가?
ExtremeInception = nn.Sequential(
nn.Conv2d(in_channels=9,
out_channels=9,
kernel_size=1,
bias=False),
nn.ReLU(),
nn.Conv2d(in_channels=9,
out_channels=9,
kernel_size=3,
groups=9,
bias=False),
nn.ReLU()
)
We remark that this extreme version of an Inception module is almost identical to a depthwise
separable convolution, an operation that has been used in neural network design as early as
2014 and has become more popular since its inclusion in the TensorFlow framework in 2016.
An extreme version of Inception module은 2014 년 초 신경망 설계에 사용되었으며 2016 년 TensorFlow 프레임 워크에
포함 된 이후 더 널리 사용되는 Depthwise Separable Convolution과 거의 동일합니다.
depthwise separable convolution 와 비슷한 형태의 모듈이 생성됩니다.
depthwise separable convolution가 궁금하시면
https://coding-yoon.tistory.com/77
[딥러닝] Depthwise Separable Covolution with Pytorch( feat. Convolution parameters VS Depthwise Separable Covolution paramet
안녕하세요. Google Coral에서 학습된 모델을 통해 추론을 할 수 있는 Coral Board & USB Accelator 가 있습니다. 저는 Coral Board를 사용하지 않고, 라즈베리파이4에 USB Accelator를 연결하여 사용할 생각입니..
coding-yoon.tistory.com
Xception을 한 번에 작성할려고 했지만 생각보다 쓸 것이 많아 2편 정도로 연장될 것 같습니다.
첫 논문 리뷰인데 부족한 부분이 많습니다. 피드백 주시면 감사하겠습니다.