올바른 분류 모델을 학습시키기 위해 데이터셋을 골고루 분할하는 것이 중요하다.
https://github.com/ewine-project/UWB-LOS-NLOS-Data-Set
GitHub - ewine-project/UWB-LOS-NLOS-Data-Set: Repository with UWB data traces representing LOS and NLOS channel conditions in 7
Repository with UWB data traces representing LOS and NLOS channel conditions in 7 different indoor locations. - GitHub - ewine-project/UWB-LOS-NLOS-Data-Set: Repository with UWB data traces represe...
github.com
예를 위해 위 Github에서 0과 1로 이루이진 이진 클래스 데이터 셋이 있다. 이 글은 데이터를 라벨에 맞게 골고루 분리하는 것이므로 데이터 분석은 따로 하지 않는다.
csv 파일은 7개이며, 총 데이터의 개수는 42000개이다.

sklearn 라이브러리에서 train_test_split을 사용하면 간단히 데이터를 분할할 수 있다. 아래 코드에서 간단히 데이터셋을 불러올 수 있다. 이 데이터셋의 경우 nlos가 클래스(혹은 정답 데이터)이다. 아래의 그림을 보게 되면 0, 1, 0, 1, 1...로 무작위로 정렬돼었다. 각 클래스의 개수를 출력하면, 21000개를 확인할 수 있다.
import uwb_dataset
import pandas as pd
columns, data = uwb_dataset.import_from_files()
for item in data:
item[15:] = item[15:]/float(item[2])
print("\nColumns :", columns.shape, sep=" ")
print("Data :", data.shape, sep=" ")
print(type(data))
df_uwb = pd.DataFrame(data=data, columns=columns)
print(df_uwb.head(10))
los_count = df_uwb.query("NLOS == 0")["NLOS"].count()
nlos_count = df_uwb.query("NLOS == 1")["NLOS"].count()
print("Line of Sight Count :", los_count)
print("Non Line of Sight Count :", nlos_count)
"""
결과
./dataset/uwb_dataset_part5.csv
./dataset/uwb_dataset_part7.csv
./dataset/uwb_dataset_part2.csv
./dataset/uwb_dataset_part3.csv
./dataset/uwb_dataset_part4.csv
./dataset/uwb_dataset_part1.csv
./dataset/uwb_dataset_part6.csv
Columns : (1031,)
Data : (42000, 1031)
<class 'numpy.ndarray'>
Line of Sight Count : 21000
Non Line of Sight Count : 21000
"""

파이썬으로 개발을 하면서 느낀 것은 최대한 반복문을 지양하고 라이브러리를 사용하는 것이다. 파이썬은 빠르게 데모 프로그램 구현에 많이 사용하는데 라이브러리가 이를 가능케 한다. 그리고 가장 큰 이유는 내가 만든 코드는 절대 라이브러리를 이길 수 없다는 것이다. 이번에 사용하고자 하는 train_test_split은 sklearn 라이브러리의 함수이다. sklearn는 머신러닝 대표 라이브러리이지만 딥러닝 사용에 있어 문제가 없다.
train_test_split : 배열 또는 행렬을 무작위 학습 및 테스트 하위 집합으로 분할.
-test_size : 0~1 사이의 값으로, 기본 test size는 0.25로 자동으로 train size는 0.75이다. 아래의 그림처럼 데이터를 분할.
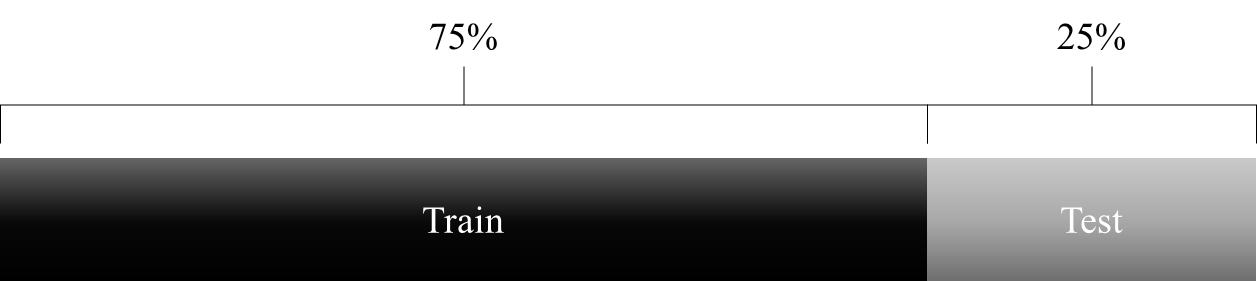
- random_state : shuffle 제어하는 인자이다. 모델의 성능을 향상시키기 위해 다양한 방법으로 모델을 디자인한다. 하지만 공정한 검증을 위해 똑같은 데이터셋을 필요로 한다. 그 때 사용하는 인자이다.
- shuffle : 분리하기 전에 데이터를 섞을지 여부.
- stratify : 가장 중요한 파라미터. 클래스에 맞게 골고루 분할할지 여부.
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(
df_uwb[["CIR"+str(i) for i in range(cir_n)]].values,
df_uwb['NLOS'].values,
test_size=0.2,
random_state=42,
shuffle=True,
stratify=df_uwb['NLOS'].values)
print("x_train shape :", x_train.shape, y_train.shape)
print("x_test shape :", x_test.shape, y_test.shape)
print("Train NLOS 0 count :", len(y_train[y_train==0]))
print("Train NLOS 1 count :", len(y_train[y_train==1]))
print("Test NLOS 0 count :", len(y_test[y_test==0]))
print("Test NLOS 0 count :", len(y_test[y_test==1]))
"""
x_train shape : (33600, 1016) (33600,)
x_test shape : (8400, 1016) (8400,)
Train NLOS 0 count : 16800
Train NLOS 1 count : 16800
Test NLOS 0 count : 4200
Test NLOS 0 count : 4200
"""
'🐍 Python > Deep Learning' 카테고리의 다른 글
| [Pytorch] Conv1D + LSTM 모델 Pytorch 구현 (0) | 2022.04.05 |
|---|---|
| [딥러닝] 딥러닝 모델을 간단하게 시각화하는 프로그램, Netron | Pytorch, ONNX (1) | 2022.03.05 |
| 주피터 노트북 테마 툴바(Toolbar) 고정 - 주피터 노트북 개인 딥러닝 서버 만들기 ! (예외편) (1) | 2021.07.20 |
| 주피터 노트북 개인 딥러닝 서버 만들기 ! (3) with Window10, Pytorch (2) | 2021.07.19 |
| 주피터 노트북 개인 딥러닝 서버 만들기 ! (2) with Window10, Pytorch (1) | 2021.07.16 |