안녕하세요.
제가 평소에 자주 즐겨보는 빵형의 개발도상국에서 재미있는 딥러닝 예제가 있어서 가져 왔습니다.
www.youtube.com/watch?v=VxRCku4Bkgg
평소에는 눈으로만 보다가 재밌어 보여서, 실제로 저도 한 번 해보기로 했습니다.
댓글을 보니, 많은 사람들이 데이터 프로세싱 부분에서 힘들어 하십니다.
저도 따라해보았더니, 학습이 진또배기가 아니라 데이터 전처리 부분이 이 동영상의 꽃이란걸 알게 됐습니다.
(역시 딥러닝은 데이터가 문제...)
1. 데이터셋 받기
www.kaggle.com/jessicali9530/celeba-dataset
CelebFaces Attributes (CelebA) Dataset
Over 200k images of celebrities with 40 binary attribute annotations
www.kaggle.com
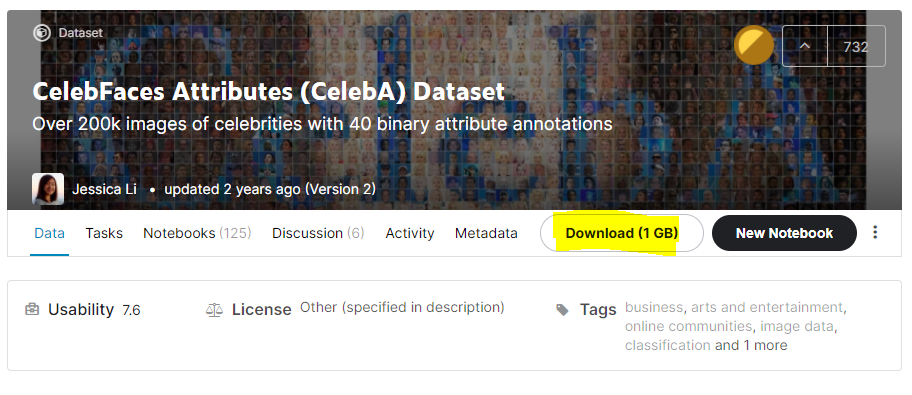
하나 주의사항 !
컴퓨터 용량은 충분하신가요?
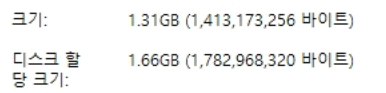
실제로 데이터를 받아보면, 1G 바이트 약간 넘습니다.
하지만, 데이터 전처리를 하게 되면

지옥을 맛보시게 될겁니다. SSD 빵빵한거나 서버가 없으면 뒤로 돌아가시는걸 추천드립니다.
2. Git에서 코드 받기
github.com/kairess/super_resolution
kairess/super_resolution
Super resolution with Subpixel CNN using Keras. Contribute to kairess/super_resolution development by creating an account on GitHub.
github.com

오늘은 preprocess.ipynb 전처리 부분을 봐보겠습니다.
옵션사항입니다.
저는 Pycharm으로 코딩을 할 예정이기 때문에 .ipynb를 .py로 변경했습니다.
jupyter nbconvert --to scripy preprocess.ipynb ( 해당 경로에서 )
3. 경로/디렉토리 준비하기
빵빵한 SSD를 준비합니다.

저는 E 드라이브에 준비하겠습니다.
E 드라이브(자신의 드라이브)에 dataset 폴더를 하나 만듭니다.
1. E:\dataset
제 기본 경로가 되겠습니다.
dataset 폴더에 이렇게 폴더를 만들어 주겠습니다.

2. E:\dataset\img
우선 img 폴더는 학습을 시킬 실제 데이터가 들어가 있습니다. 아까 kaggle에서 받은 img_align_celeba를 옮겨서 이름만 바꿔준 것입니다. 그대로 사용하셔도 상관없습니다. 저는 간단한게 좋아서 img로 바꿨습니다.
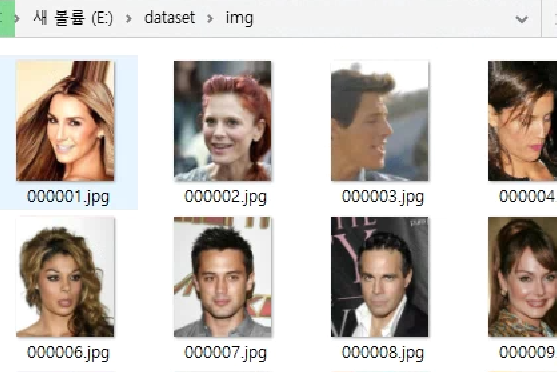
이 img 폴더에 있는 사진들은 학습할 데이터입니다. 간단히 X_data라 부르겠습니다.
X_data는 Train용, Validation용, Test용으로 나뉩니다.
3. E:\dataset\list_eval_partion.csv
이미지에 각각 라벨링 한 것을 csv파일로 저장되있습니다. 다른 csv 파일은 그냥 휴지통에 던져 줍니다.

partition : 1 => train (162770장)
partition : 2 => val (19867장)
partition : 3 => test (19962장)
4. E:\dataset\x_train
이제 데이터를 전처리하게 되면 train, validation, test 용으로 데이터가 나뉘기 때문에
저 이름 그대로 폴더를 만들어 주어야 합니다.
x_train
x_val
x_test
y_train
y_val
y_test
이 폴더 안에는 학습하기 좋게끔 numpy(.npy) 로 전처리되어 저장될 예정입니다.
굳이 몰라도 되지만, TMI로 scipy나, matplotlib 등 여러 과학, 수학, 딥러닝에서 numpy를 제공하는 이유는
numpy가 C코드로 작성된 라이브러리이기 때문에 파이썬 내장 list보다 속도가 훨씬 빠릅니다.
파이썬 개발한 사람이 C 개발자였으니...
4. 코드
import os, cv2
import numpy as np
from skimage.transform import pyramid_reduce
# 경로
base_path = r'E:\dataset' # E:\dataset
img_path = os.path.join(base_path, 'img') # E:\dataset\img
eval_list = np.loadtxt(os.path.join(base_path, 'list_eval_partition.csv'), dtype=str, delimiter=',', skiprows=1)
print(eval_list[0])
# 이미지 확인
img_sample = cv2.imread(os.path.join(img_path, eval_list[0][0]))
print(os.path.join(img_path, eval_list[0][0]))
h, w, _ = img_sample.shape
# 이미지 전처리
crop_sample = img_sample[int((h-w)/2):int(-(h-w)/2), :]
resized_sample = pyramid_reduce(crop_sample, downscale=4)
pad = int((crop_sample.shape[0] - resized_sample.shape[0]) / 2)
padded_sample = cv2.copyMakeBorder(resized_sample, top=pad, bottom=pad, left=pad, right=pad, borderType=cv2.BORDER_CONSTANT, value=(0,0,0))
print(crop_sample.shape, padded_sample.shape)
# main
downscale = 4
n_train = 162770
n_val = 19867
n_test = 19962
for i, e in enumerate(eval_list):
filename, ext = os.path.splitext(e[0])
img_path = os.path.join(img_path, e[0])
img = cv2.imread(img_path)
h, w, _ = img.shape
crop = img[int((h-w)/2):int(-(h-w)/2), :]
crop = cv2.resize(crop, dsize=(176, 176))
resized = pyramid_reduce(crop, downscale=downscale)
norm = cv2.normalize(crop.astype(np.float64), None, 0, 1, cv2.NORM_MINMAX)
if int(e[1]) == 0:
np.save(os.path.join(base_path, 'x_train', filename + '.npy'), resized)
np.save(os.path.join(base_path, 'y_train', filename + '.npy'), norm)
elif int(e[1]) == 1:
np.save(os.path.join(base_path, 'x_val', filename + '.npy'), resized)
np.save(os.path.join(base_path, 'y_val', filename + '.npy'), norm)
elif int(e[1]) == 2:
np.save(os.path.join(base_path, 'x_test', filename + '.npy'), resized)
np.save(os.path.join(base_path, 'y_test', filename + '.npy'), norm)
5. 오류
아마 유튜브를 보고 따라하시는 분들 중에 대부분이 경로 문제입니다.
----------------------------------------------------------------------------------------------------------------------------

대표적으로 이 분이 경로 문제로 막히신겁니다.
Git에서 코드를 받으실 때 DataGenerator.py 도 같이 받으십니다.

DataGenerator는 x_train 등 전처리한 .npy 파일을 불러와서 Batch로 묶고 shuffle 하여 데이터셋을 만드는 코드입니다.
하지만 에러문을 보게 되면, splited = ID.split('/') 에서 오류가 발생합니다.
ID.split('/')는 불러온 경로를 '/' 기준으로 나누는 것입니다.
예를 들어
'E:/dataset/img' 가 있습니다.
'E:/dataset/img'.split('/')을 하게 되면 ["E:", "dataset", "img"]로 나뉩니다.
눈치 빠르신 분이 있을까요??
제 코드에서 기본 경로는 r'E:\dataset' 입니다.
r'E:\dataset'.split('/")는 어떻게 될까요?
결과는 ["r'E:\dataset'.split('/")"] 입니다. 우리들은 기본 경로를 절대경로로 표시했습니다.
"\"는 "/" 아닙니다!!!!! 우리는 DataGenerator.py에 들어가서 splited = ID.split('/')를
splited = ID.split('\')로 변경해주면 해결됩니다.
ID가 왜 경로죠? 라고 궁금해하는 분이 계실 수도 있습니다.

__data_generation 함수에서 list_IDS_temp라는 파라미터를 받는 것을 알 수 있습니다.
list_IDS_temp가 무엇인지 확인하겠습니다.

list_IDs에서 받아온거네요. list_IDs가 무엇인지 역추적해보겠습니다.

아하 DataGenerator에서 생성자에서 파라미터로 받는 것을 확인했습니다. 맨 처음 파라미터니까 찾기 쉽겠네요.
아마 데이터를 생성하는 클래스이기 때문에 train.py에서 사용했을겁니다.

네. import 한 것을 바로 확인할 수 있습니다.

x_train_list = list_IDs 라는 것을 역추적해 알 수 있게 되었습니다.
위 댓글 분의 오류의 원인은 경로 문제라는 것을 제대로 확인할 수 있습니다.
----------------------------------------------------------------------------------------------------------------------------

'NoneType' object has no attribute 'shape'
shape라는 속성이 없다라는 오류입니다.
아마 shape를 쓴 걸로 보아 NoneType 자리에는 Numpy가 들어갈 수 있다는걸 추측할 수 있습니다.
그런데 NoneType 이라는 것은 해당 경로에 .npy를 불러 왔지만 경로가 잘못되어 아무 것도 불러오지 못하였다고 말할 수 있습니다.
----------------------------------------------------------------------------------------------------------------------------
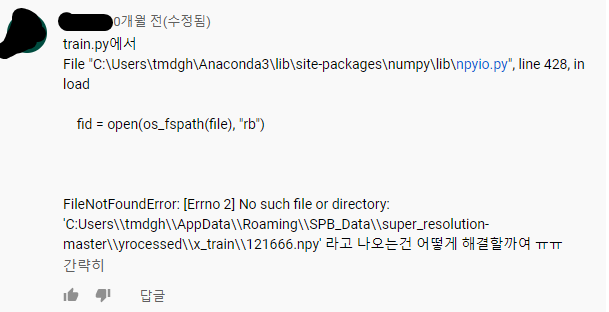
이것도 경로 문제입니다.
에러문에 나와있네요.
No such file or directory 파일이나 폴더를 찾을 수 없다...!
아마 경로를 확인해보니 첫 번째 오류와 비슷한 것 같습니다.
경로구분이 "\\"으로 되있는데 split은 "/" 이니 제대로 분리가 되지 않았을겁니다.
np.load( 경로 ) 에서 막힌 듯 싶습니다. !!
----------------------------------------------------------------------------------------------------------------------------

이건 제가 올린 답글...
도움이 되셨으면 좋겠습니다... 글을 마치도록 하겠습니다아아... 빵형 개발도상국님 항상 재밌게 잘 보고 있습니다!