in particular the VGG-16 architecture , which is schematically similar to our proposed architecture
in a few respects.
특히 VGG-16계층은 몇 가지 측면에서 Xception 계층과 개략적으로 유사합니다.
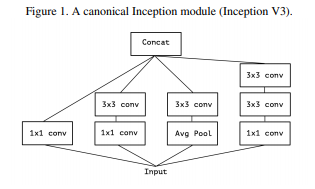
The Inception architecture family of convolutional neural networks, which first demonstrated the
advantages of factoring convolutions into multiple branches operating successively on channels and then on
space.
Inception 모듈이 여러가지 방향으로 채널과 공간에서 작동하는 장점을 소개하고 있다는 내용입니다.
Depthwise separable convolutions, which our proposed architecture is entirely based upon. ~~
앞 쪽에서 이야기한 Depthwise Separable Convolution의 연산량 감소로 인한 속도 증가의 장점을 소개하고
있습니다.
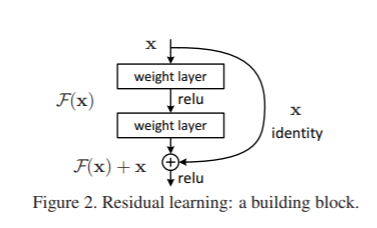
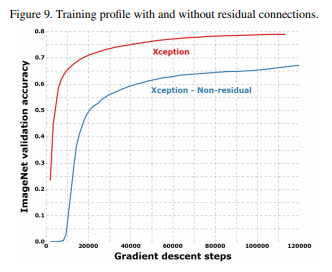
Residual Connections를 짚고 넘어가자면, Resnet의 배경은 히든레이어가 증가함에 따라 학습이 더 잘되어야 하지만, 오히려 학습을 못하는 현상이 발생합니다. 이 현상이 vanishing/exploding gradients (기울기 손실) 문제입니다. Batch Normalization으로 어느정도 해결할 수 있지만, 근본적인 문제를 해결할 수 없습니다. 그래서 고안된 방법이 Residual Connection(mapping) 입니다. 이전의 값을 더해줌으로 기울기 손실을 방지하는 것입니다. 간단한 방법이지만 효과는 굉장히 좋습니다.
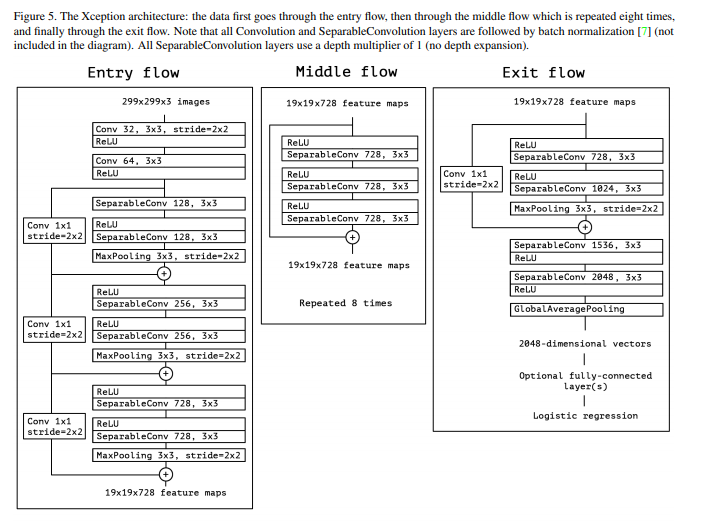
class Xception(nn.Module):
def __init__(self):
super(Xception, self).__init__()
self.entry_flow = entry_flow()
self.middle_flow = middle_flow()
self.exit_flow = exit_flow()
def forward(self, x):
x = self.entry_flow(x)
x = self.middle_flow(x)
x = self.exit_flow(x)
return x
3. Experiment result
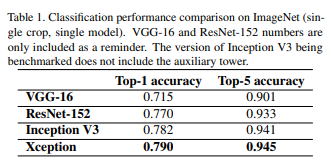
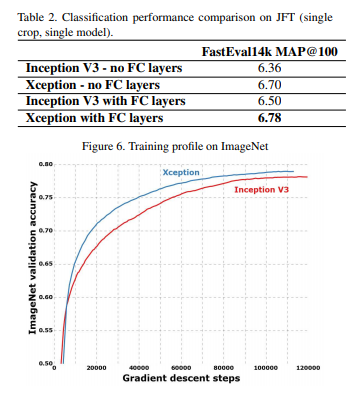
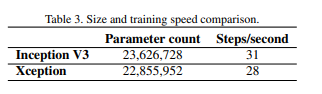
다른 모델에 비해 높은 accuracy연산량 감소Residual Connection의 성능
4. Conclusions
Depthwise Separable Convolution이 Inception 모듈과 유사하지만, Standard Convolution 만큼 사용하기 쉽고, 높은 성능과 연산량 감소의 장점 때문에 CNN의 설계의 기초가 될 것으로 기대가 됩니다. Xception 논문 리뷰를 마치도록 하겠습니다. 첫 논문 리뷰인지라 말하고자 하는 내용을 명확하게 설명하지 못하였습니다. 혹시라도 보시다가 잘못된 부분이나 추가해야할 부분이 보이시면 피드백 주시면 감사하겠습니다.
An Extreme version of Inception module과 Depthwise Separable Convolution는 굉장히 비슷한 형태를 가지고 있습니다.
논문에서 소개하는 두 개의 차이점을 설명하고 있습니다.
Two minor differences between and “extreme” version of an Inception module and a depthwise separable
convolution would be:
“extreme” version of an Inception module과 depthwise separable
convolution의 두 가지 사소한 차이점은 다음과 같습니다.
1. Order(순서)
• The order of the operations:
depthwise separable convolutions as usually implemented (e.g. in TensorFlow)perform first channel-wise
spatial convolution and then perform 1x1 convolution, whereas Inception performs
the 1x1 convolution first.
An Extreme version of Inception module : Pointwise Convolution , Depthwise Convolution(3x3, 5x5 ...)
Convolution의 순서가 다르다고 합니다.
We argue that the first difference is unimportant, in particular because these operations are meant
to be used in a stacked setting.
스택 설정에서 사용되기 때문에 순서의 차이점은 중요하지 않다고 합니다.
2. Non-Linearity(비선형성)
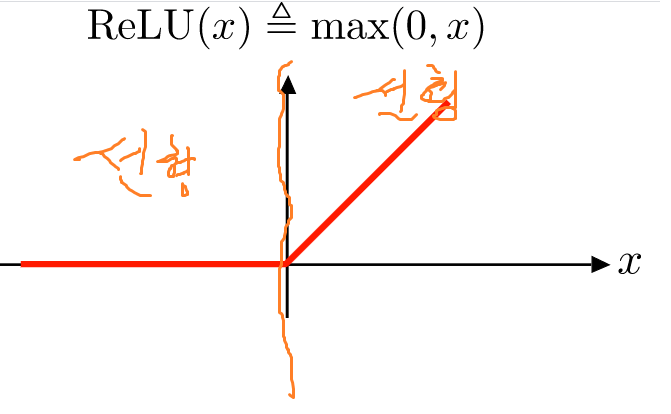
• The presence or absence of a non-linearity after the first operation.
In Inception, both operations are followed by a ReLU non-linearity, however depthwise separable
convolutions are usually implemented without non-linearities.
ReLU(비선형)의 유무.
Inception은 Convolution 수행이 후 ReLU가 붙는 반면,
일반적으로 Depthwise Separable Convolution는 ReLU가 없이 구현됩니다.
The second difference might matter, and we investigate it in the experimental section
(in particular see figure 10).
ReLU의 유무는 중요하며, Figure 10에서 실험 결과를 보여줍니다.
Depthwise Separable Convolution에서 ReLU를 사용하지 않았을 때 더 높은 Accruacy를 보여줍니다.
It may be that the depth of the intermediate feature spaces on which spatial convolutions are applied
is critical to the usefulness of the non-linearity:
for deep feature spaces (e.g. those found in Inception modules) the non-linearity is helpful,
but for shallow ones (e.g. the 1-channel deep feature spaces of depthwise separable convolutions) it becomes harmful,
possibly due to a loss of information.
깊은 특징 공간의 경우, ReLU가 도움이 되지만 얕은 공간( 1x1 Convolution )에서는 ReLU에 의해 정보 손실이 생길 수 있기 때문에 사용하지 않는 것이 좋다는 결과입니다.
다음 글은 Xception의 Architecture에 대해 설명하고, Pytorch로 구현함으로 글을 Xception 논문 리뷰를 마치도록 하겠습니다. 피드백주시면 감사하겠습니다.
This observation naturally raises the question:
이 관찰은 당연히 문제를 제기합니다.
what is the effect of the number of segments in the partition (and their size)?
파티션의 세그먼트 수 (및 크기)는 어떤 영향을 미칩니까?
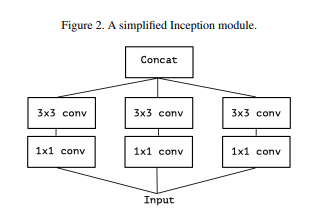
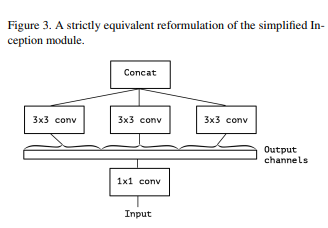
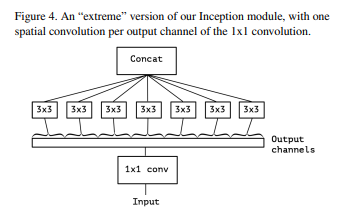
4. Extreme version of Inception module
Figure3에서 Output Channels를 최대로 그룹을 지어 분리하여 수행하면 어떨까?
We remark that this extreme version of an Inception module is almost identical to a depthwise
separable convolution, an operation that has been used in neural network design as early as
2014 and has become more popular since its inclusion in the TensorFlow framework in 2016.
An extreme version of Inception module은 2014 년 초 신경망 설계에 사용되었으며 2016 년 TensorFlow 프레임 워크에
포함 된 이후 더 널리 사용되는 Depthwise Separable Convolution과 거의 동일합니다.
depthwise separable convolution 와 비슷한 형태의 모듈이 생성됩니다.