이번 글은 주피터 노트북을 좀 더 유용하고 보기 좋게 만들기 위한 편입니다. 굳이 안 하시고 넘어가셔도 무방합니다.
~ 1. 주피터 노트북 테마 ~
저는 주피터 노트북 기본 테마를 별로 좋아하지 않습니다. 현재 제가 다니고 있는 연구실은 정부에서 지원하는 딥러닝 서버를 주피터 노트북으로 이용하고 있습니다. 저만 사용하는 것이 아니기 때문에, 기본 테마로 뒀습니다.
하지만 이 딥러닝 서버는 오로지 저만을 위한 서버이기 때문에 테마를 바꾸겠습니다.
anaconda prompt를 들어가 pip install jupyterthemes 를 입력해 테마 패키지를 설치합니다.
pip install jupyterthemes # 주피터 노트북 테마 패키지 설치
jt -l # 테마 목록 출력
"""
Available Themes:
chesterish
grade3
gruvboxd
gruvboxl
monokai
oceans16
onedork
solarizedd
solarizedl
"""
저는 테마 grade3이 제일 좋아합니다.
jt -t grade3 -T -N
-T : 툴바 보이게 설정 -N : 제목 보이게 설정
툴바는 무조건 있는게 편합니다. 제목은 내가 현재 어떤 파일을 편집하는지 알기 편하고, 제목을 누르면 수정할 수 있어 편합니다. 이 정도 설정하시면 문제없습니다. 폰트 사이즈나 다양한 설정이 있지만 그건 구글에 치면 많은 블로그가 있습니다.
툴바제목jt -t grade3 -T -N
~ 2. 주피터 노트북 확장 프로그램 ~
확장프로그램은 사람들이 추천하는 것을 사용하면 편합니다. 아래 블로그 분께서 추천하시는 것들을 하시면 편합니다.
Anaconda를 설치합니다. 2021.07.14 기준 Python3.8과 주피터 노트북이 설치됩니다.
( 따로 경로는 설정할 필요는 없기 때문에, 기본 경로 설정으로 설치합니다. )
설치를 완료하면.
위 그림처럼 설치된 파일들을 확인할 수 있습니다.
우리에게 필요한 것은 Anaconda Prompt (anaconda3) 와 Jupyter Notebook (anaconda3)입니다.
~ 2. 주피터 노트북 설정을 위한 파일 생성 ~
Anaconda Prompt를 들어가서 아래의 명령어를 입력합니다.
jupyter notebook --generate-config
위 명령어는 주피터 노트북의 설정 파일(. py)을 생성하는 의미입니다.
Window User -> C:/Users/"사용자 이름"/.jupyter Linux User -> /home/"사용자 이름"/.jupyter
저는 주피터 노트북 테마, 확장 프로그램을 건드렸기 때문에 많은 파일들이 있지만, 처음 설정하시는 분들께서는jupyter_notebook_config.py만 있습니다.
저처럼 코드 편집기가 없으시면 메모장으로 들어가서 작업하시면 됩니다.
코드를 편집하기 전에, 자신의 로컬(private) IP와 포트포워딩을 위한 포트 번호를 지정해야 합니다.
~ 3. IP 확인, 고정, 포트포워딩 ~
3.1. IP 확인, 고정 (공인 IP, 사설 IP)
우선, 간단히 IP의 종류에는 두 가지가 있습니다.
외부에서 받아 오는 공인(Public) IP (외부), 공유기에서 나눠주는 로컬(private) IP (내부)가 있습니다.
1. 공인 IP
공인 IP를 확인하는 방법은 여러 가지가 있습니다. 간단히 네이버에서 내 아이피 보기를 검색하시면 자신의 공인 IP를 확인할 수 있습니다.
첫번 째 방법.
두 번째, 192.168.0.1( 공유기 관리자 모드 )를 url을 통해 들어간다. 로그인 창이 뜨는데, 처음 자신이 설정한 아이디와 비밀번호를 입력한다. ( 잊었을 시, 리셋 )
저는 ipTIME을 사용합니다. ( 공유기마다 환경이 다릅니다. ) ipTIME은 외부 IP 주소라고 바로 확인할 수 있습니다.
공인 IP를 알아야 하는 이유는 나중에 외부에서 주피터 노트북 서버를 접근하기 위해 필요합니다.
( 간단히, 위 공인 IP를 우리가 구매했기 때문에, 우리가 네이버에서 확인한 공인 IP는 유일무이합니다. 하지만, 사설 IP는 공유기가 랜덤 하게( 혹은 우리가 직접 ) 만들어 주기 때문에, 굉장히 많습니다. )
2. 사설 IP
쉽게 설명하자면, 192.168.0.xx의 규칙을 가지는 IP는 모두 사설 IP입니다. cmd에서 ipconfig를 입력하면 됩니다.
혹은, 공유기 관리자 모드를 들어가 확인하는 것입니다.
① 보통 사설 IP는 자동으로 할당되어 IP가 박스 1의 IP주소 대여 범위 안에서 수시로 변경됩니다. 오늘은 cmd에서 확인한 것처럼 192.168.0.15이지만, 내일은 192.168.0.16으로 IP가 변경될 수 있습니다.
② 박스 2의 사용 중인 IP 주소 정보를 보시면, 현재 와이파이 등 공유기에 물려 있는 기기들을 확인할 수 있습니다. 저는 192.168.0.15를 그대로 사용하겠습니다.
③ 현재 사용 중인 IP를 클릭하면 자동으로 IP, mac 주소까지 입력되니 설명은 자신이 구별할 수 있게 적고 수동 등록합니다. 그러면 박스 3에서처럼 리스트에 저장되어 고정됩니다.
약간의 이해를 위해 태블릿으로 저희 집 네트워크 상태를 그려 봤습니다.
우리들이 접근하고자 하는 서버는 50.0.x.x의 192.168.0.15 서버입니다. 하지만, 우리가 브라우저에 IP를 치고 들어갈 때, 저런 식으로 입력하나요? 아닙니다.
그래서 나온 것이 포트 번호입니다. ( 정확히는 이 때문에 나온 것은 아닙니다. IP는 네트워크(3) 계층, Port 번호는 전송(4) 계층으로 네트워크 구조를 자세히 알아야 합니다. 통신 전공자가 아니라면, 이 정도만 이해해도 충분하다고 생각이 듭니다. ) 우리가 사용하고자 하는 50.0.x.x의 192.168.0.15 대신 50.0.x.x:{port number}를 입력합니다. (대표적으로 포트번호 http는 80, ssh는 22, 주피터 노트북 서버의 디폴트 포트번호는 8888입니다. 주피터 노트북을 아무 설정 없이 실행하면, localhost:8888로 들어가게 됩니다. )
8888로 그대로 사용해도 됩니다. 우리들은 보안 전공이 아니지만, 적어도 포트번호를 다르게 써서 그나마 안전하게 접근할 수 있도록 할 예정입니다.
3.2. 포트포워딩
포트포워딩은 공유기에게 문을 열어주는 역할을 합니다. 우리가 주피터 노트북 기본 포트번호가 8888인 것은 알지만, 공유기는 알지 못합니다. 이를 공유기에게 지정하는 것입니다. 만약 50.0.x.x에서 포트번호 8888을 만났다면, 여기로 가세요. 정도로 이해하시면 될 것 같습니다.
우리는 기본 주피터 노트북 포트 번호를 그대로 사용하지 않고 jupyter_notebook_config.py에서 포트 번호를 바꿔줍니다. 포트번호는 0부터 65535까지 범위(16bit = 2^16)를 사용합니다. 위에서 언급했듯이, HTTP는 80, SSH는 22 등 이미 사용되고 포트 번호가 있습니다. Well Known Port Number이라고 합니다. 이 숫자들을 피해 저는 3333이라는 포트 번호를 주피터 노트북 포트 번호로 사용하겠습니다. 다른 숫자를 쓰고 싶으신 분은 위 유의사항을 피해 사용하시면 됩니다.
저와 같은 ipTIME 공유기라면, 저를 따라 하시면 됩니다. 하나씩 설명해드리겠습니다.
규칙 이름 : 사용자 마음대로
IP 주소 : 자신이 딥러닝 서버로 만들고자 하는 로컬 IP
프로토콜 : TCP
외부포트 : 7777 ( 그림에서 설명하겠습니다. )
내부포트 : 3333 ( 주피터 노트북 서버 포트 번호)
어렵게 생각하실 필요 없습니다.
50.0.x.x:7777로 접근했다면...
"7777포트는 3333포트를 가리키는구나."
50.0.x.x:3333으로 길을 안내해줍니다. 3333포트는 192.168.0.15의 주피터 노트북 서버를 가리킵니다.
만약 나는 8888 그대로 사용하겠다 싶으시면, 외부포트 8888, 내부포트 8888 그대로 사용하시면 됩니다. 솔직히 문제되진 않습니다. 누가 개인 서버를 털겠습니까? 털어갈 것도 없으니...
~ 4. 주피터 노트북 설정 ~
Anaconda Prompt에서 jupyter_notebook_config.py를 위에서 생성했습니다. 경로는 아래와 같이
Window User -> C:/Users/"사용자 이름"/.jupyter Linux User -> /home/"사용자 이름"/.jupyter
jupyter_notebook_config.py를 메모장 혹은 코드 편집기로 열어 줍니다. 아마 알 수 없는 코드들이 작성되있습니다. 하지만 대부분이 주석이기 때문에 실제 코드는 얼마되지 않으니 걱정안하셔도 됩니다. ( 파이썬 주석은 #입니다. 주석은 설명입니다. )
4.1. 주피터 노트북 포트번호 설정
## The port the notebook server will listen on (env: JUPYTER_PORT).
# Default: 8888
c.NotebookApp.port = 3333 # 자신이 원하는 포트 번호
4.2. 주피터 노트북 비밀번호 설정
## Hashed password to use for web authentication.
#
# To generate, type in a python/IPython shell:
#
# from notebook.auth import passwd
# passwd()
#
# The string should be of the form type:salt:hashed-password.
# Default: ''
# c.NotebookApp.password = password
아마 기본적으로 위 같이 주석처리가 되있을 것입니다. 아래와 같이 주석을 해제하고 자신이 원하는 비밀번호를 작성하시면 됩니다. jupyter_notebook_config.py이 파이썬 코드이기 때문에 괜찮습니다.
## Hashed password to use for web authentication.
#
# To generate, type in a python/IPython shell:
#
from notebook.auth import passwd
password = passwd('자신이 원하는 비밀번호') # 기본으로 argon2를 사용
# password = passwd('자신이 원하는 비밀번호', 'sha256') # option : 'sha1', 'sha256'...
#
# The string should be of the form type:salt:hashed-password.
# Default: ''
c.NotebookApp.password = password
4.3. 주피터 노트북 IP 설정
## The IP address the notebook server will listen on.
# Default: 'localhost'
c.NotebookApp.ip = '192.168.0.15'
## Whether to open in a browser after starting. The specific browser used is
# platform dependent and determined by the python standard library `webbrowser`
# module, unless it is overridden using the --browser (NotebookApp.browser)
# configuration option.
# Default: True
c.NotebookApp.open_browser = False
4.6.주피터 노트북 작업 경로 설정
의외로 작업 경로 설정하는 것이 복병이었습니다. 코드 상에서 작업 경로를 제대로 입력하더라도 Home 경로로 이동해버립니다. 아래 블로그 분께서 친절하게 문제점을 알려주시니 그대로 보고 따라 하시면 됩니다.
Plain Network(단순히 Layer을 깊게 쌓음)에서 발생하는 Vanishing Gradient(기울기 소실), Overfitting(과적합) 등의 문제를 해결하기 위해 ReLU, Batch Nomalization 등 많은 기법이 있습니다.
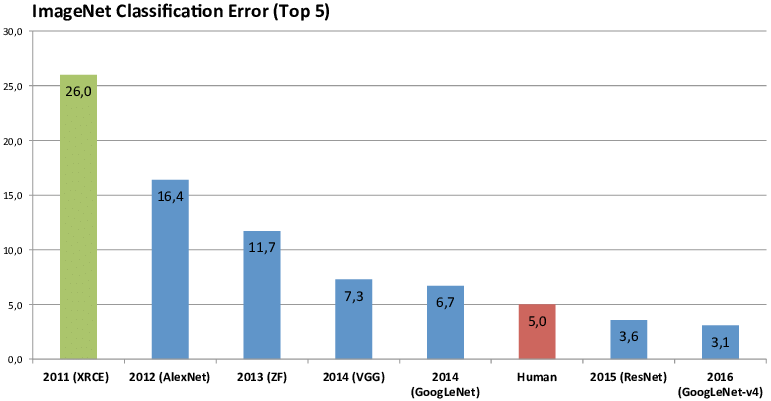
ILSVRC Challenge2021년 3월 24일 기준 인용
ILSVRC 대회에서 2015년, 처음으로 Human Recognition보다 높은 성능을 보인 것이 ResNet입니다.
그 위용은 무지막지한 논문 인용 수로 확인할 수 있습니다.
그렇기 때문에 ResNet은 딥러닝 이미지 분야에서 바이블로 통하고 있습니다.
Plain Netwrok Vs ResNet
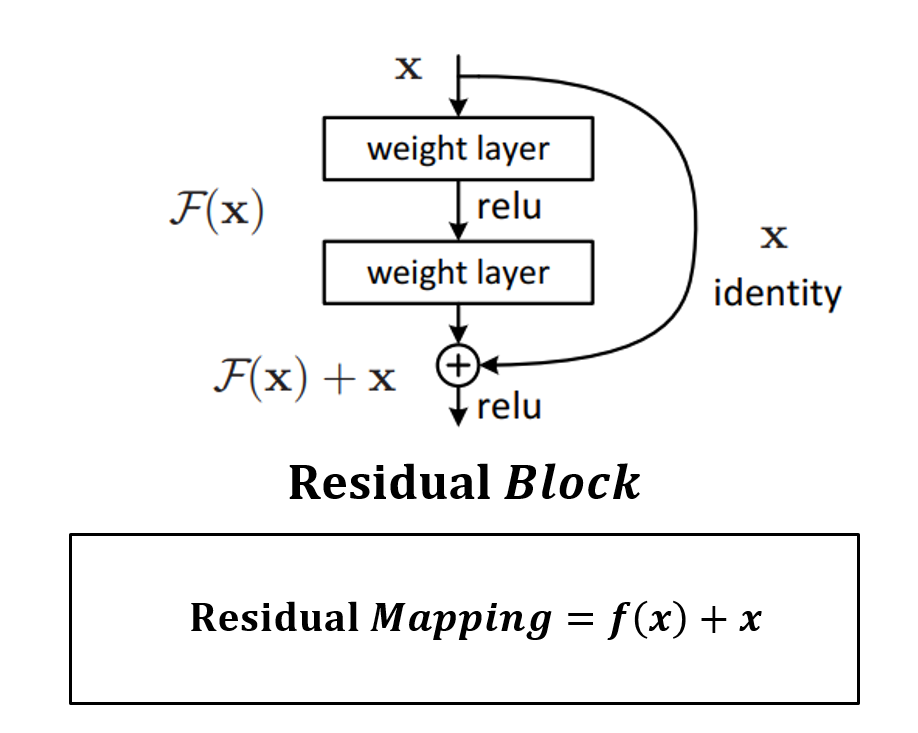
Plain Network는 단순히 Convolution 연산을 단순히 쌓는다면, ResNet은 Block단위로 Parameter을 전달하기 전에 이전의 값을 더하는 방식입니다.
Residual Block
F(x) : weight layer => relu => weight layer
x : identity
weight layer들을 통과한 F(x)와 weight layer들을 통과하지 않은 x의 합을 논문에서는 Residual Mapping 이라 하고, 그림의 구조를 Residual Block이라 하고, Residual Block이 쌓이면 Residual Network(ResNet)이라고 합니다.
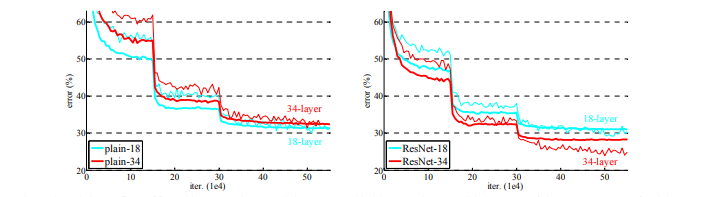
Residual Mapping은 간단하지만, Overfitting, Vanishing Gradient 문제가 해결되어 성능이 향상됐습니다.
그리고 다양한 네트워크 구조에서 사용되며, 2017년 ILSVRC을 우승한 SeNet에서 사용됩니다. ( 이 글을 쓴 이유이기도 합니다. )
Plain Network VS ResNet (Error)
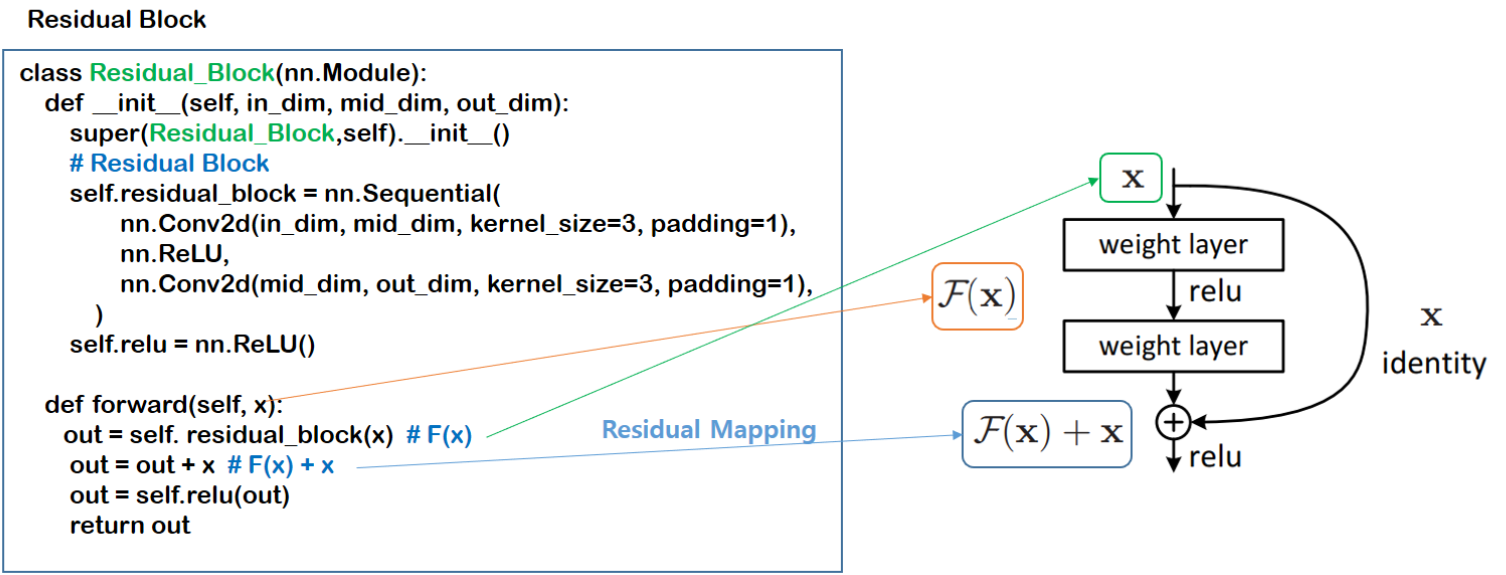
Residual Block
class Residual_Block(nn.Module):
def __init__(self, in_dim, mid_dim, out_dim):
super(Residual_Block,self).__init__()
# Residual Block
self.residual_block = nn.Sequential(
nn.Conv2d(in_dim, mid_dim, kernel_size=3, padding=1),
nn.ReLU,
nn.Conv2d(mid_dim, out_dim, kernel_size=3, padding=1),
)
self.relu = nn.ReLU()
def forward(self, x):
out = self. residual_block(x) # F(x)
out = out + x # F(x) + x
out = self.relu(out)
return out
그리고 Residual Block 소개 후 BottleNeck이 나옵니다. 아래 글을 참고하시면 좋을 것 같습니다.
CNN에서 CIR Featur을 추출, Redundant information을 제거하고, LSTM을 이용하여 분류합니다.
( CNN+stacked-LSTM Accuracy : 82.14% )
Model StructureCNN StructureLSTM StructureResult
Implemnet ( Dataset : df_uwb_data 준비 )
1. Import
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
from torch.utils.tensorboard import SummaryWriter
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import time
import random
import uwb_dataset
print("Pytorch Version :", torch.__version__) # Pytorch Version : 1.7.1+cu110
writer = SummaryWriter('runs/UWB_CIR_Classfication')
%matplotlib inline